Taming Transformers for High-Resolution Image Synthesis (סקירה)

סקירה זו היא חלק מפינה קבועה בה אני סוקר מאמרים חשובים בתחום ה-ML/DL, וכותב גרסה פשוטה וברורה יותר שלהם בעברית. במידה ותרצו לקרוא את המאמרים הנוספים שסיכמתי, אתם מוזמנים לבדוק את העמוד שמרכז אותם תחת השם deepnightlearners.
לילה טוב חברים, היום אנחנו שוב בפינתנו deepnightlearners עם סקירה של מאמר בתחום הלמידה העמוקה. היום בחרתי לסקירה את המאמר שנקרא:
Taming Transformers for High-Resolution Image Synthesis
פינת הסוקר:
המלצת קריאה ממייק: חובה ללא ספק!
בהירות כתיבה: גבוהה
ידע מוקדם: הבנה טובה בגאנים, טרנספורמרים ו VQ-VAE די הכרחית להבנת המאמר.
יישומים פרקטיים אפשריים: יצירת תמונות באיכות מרהיבה (לא פחות!!).
פרטי מאמר:
לינק למאמר: זמין להורדה.
לינק לקוד: זמין כאן (בנוסף יש עוד 3 מימושים ״לא רשמיים״).
פורסם בתאריך: 21.06.21, בארקיב (v3).
הוצג בכנס: CVPR 2021.
תחומי מאמר:
- מודלים גנרטיביים ליצירת דאטה בתחום הויזואלי
ידע מוקדם:
- VQ-VAE
- גאנים
- טרנספורמרים
תמצית מאמר:

מודלים גנרטיביים ליצירת פיסות דאטה חדשות בתחום הויזואלי הגיעו לתוצאות מרשימות ב-3 השנים האחרונות. מודלים גנרטיביים כמו StyleGAN3 ו-VQ-VAE2 מצליחים לגנרט תמונות באיכות מאוד גבוהה במגוון רזולוציות. יתרה מזו התמונות הנוצרות באמצעות מודלים אלו נראות ממש פוטוריאליסטיות וכבר לא ניתן להבחין בין תמונה מגונרטת ל"טבעית".
רוב המודלים הגנרטיביים בעלי ביצועי SOTA בדומיין הויזואלי הינם גאנים בעלי ארכיטקטורה מבוססת על שכבות קונבולוציה (למרות שבשנה האחרונה VAE-ים, מודלי דיפוזיה ו- גישות אחרות התחילו להחזיר להם מלחמה). ביצועים עדיפים של רשתות קונבולוציה בדומיין הזה נובעים מה- "inductive bias" האינהרנטי שמאפיין רשתות מסוג זה. Inductive bias של רשתות קונבולוציה מנצל תלויות לוקאליות חזקות הקיימות בתמונות הטבעיות. לעומת זאת לטרנספורמרים אין bias כזה שמקשה עליהם ללמוד את האופיינים של התפלגות הדאטה בדומיין התמונות הטבעיות. עקב כך רוב הרשתות מבוססות טרנספורמרים בדרך כלל:
- או מצוידות ב-backbone הבנוי משכבות קונבולוציה להפקת פיצ'רים ״לֹוקאליים״
- או מוסיפים את ה-inductive bias לטרנספורמרים, כלומר נותנים יותר משקל לקשרים בין פאצ'ים קרובים בתמונה.
המאמר הנסקר שילב את שתי הגישות הנ״ל ועשה את הדבר הבא:
- אימון של VAE שבו הן המקדד והן המפענח הינם רשתות קונבולוציה. למעשה המחברים השתמשו ב-VAE מקוונטט בו המרחב הלטנטי (המכיל פלטים של המקדד) הוא למעשה אוסף דיסקרטי של וקטורים הנקרא codebook; ארחיב על זה בהמשך).
- שימוש בטרנספורמר (ובפרט במפענח שלו) עם תיבול קל של ״inductive bias" המתאים לדומיין התמונות, בשביל ללמוד את ההתפלגות מעל המרחב הלטנטי הדיסקרטי.
- גנרוט של תמונה מתחיל מיצירה של וקטור לטנטי באמצעות הטרנספורמר המאומן. לאחר מכן מזינים את הוקטור הנוצר לרשת המפענחת של הטרנספורמר ליצירת תמונה.

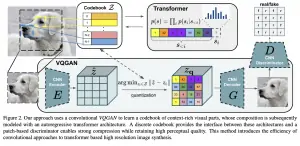
עד כאן הכל טוב ויפה אבל בשם של המאמר מופיע גם מילה GAN והוא לא הוזכר עד עכשיו. למעשה VAE מהשלב הראשון מאומן בצורה לא סטנדרטית. לפונקציית הלוס הרגילה של VQ-VAE (שגם עברה מתיחת פנים) מוסיפים את פונקציית הלוס הסטנדרטית של הגאן. כלומר בנוסף למקדד ולמפענח של VQ-VAE מאמנים דיסקרימינטור D. מטרתה של D היא לזהות אם התמונה שנוצרה באמצעות המפענח של VQ-VAE או שזו תמונה אמיתית.
למעשה VQ-GAN היא ״חתונה משולשת״ ומוצלחת במיוחד של VQ-VAE, גאן והטרנספורמר.
הסבר של רעיונות בסיסיים:
אחרי שהבנו מה מה הן אבני הבנייה העקריים של VQ-GAN בואו נצלול לפרטים נבין איך החיה המורכבת הזאת עובדת. בשביל להסביר את אופן האימון של VQ-GAN אנו קודם כל נרענן בזכרון מה זה VQ-VAE שעל בסיסו בנוי שלב האימון הראשון של VQ-GAN.
?VQ-VAE מה זה
VQ-VAE הינו סוג של (Variational AutoEncoder (VAE בעל מרחב לטנטי סופי (אך מאוד גדול). נזכיר ש- VAE רגיל הוצע ב- 2014 על ידי Kingma ו- Welling. למעשה VAE מהווה הכללה של AutoEncoder סטנדרטי שהוא שיטה להורדת מימד לא לינארית. החידוש של VAE יחסית לאוטו-אנקודר הוא תוספת של הדרישה על התפלגות הייצוגים הלטנטיים של דאטה. כלומר בנוסף לכך ייצוג לטנטי של דאטה צריך לשמר את התכונותיו החשובות, וקטורי הייצוג עצמם צריכים להיות מפולגים לפי התפלגות נתונה (לרוב גאוסית סטנדרטית). תוספת זו מאפשרת לגנרט דאטה חדש באמצעות המפענח של VAE כאשר הקלט אליו הוא וקטורי ייצוג הנדגמים מהתפלגות זו. פונקצית לוס של VAE מורכבת מסכום של לוס השחזור הריבועי (המודד עד כמה טוב הצלחנו לשחזר את הקלט) ואיבר רגולריזציה הכופה התפלגות נתונה על הפלט של האנקודר (מרחק KL).
VQ-VAE הינו מודיפיקציה של VAE שבה המרחב הלטנטי (הנקרא codebook) הוא למעשה דיסקרטי ומכיל מספר סופי של וקטורי הייצוג. כדי לגנרט פיסת דאטה חדשה בוחרים וקטור מהמרחב הדיסקרטי הזה (שמכיל כמות עצומה של וקטורים ולכן בכל זאת מאפשר גנרוט של דאטה מאוד מגוון) ומעבירים אותו דרך המפענח המאומן.
כאשר משתמשים ב- VQ-VAE עבור יצירת תמונות בדרך כלל מחלקים תמונה ל- M פאצ'ים כאשר כל פאץ' מקדד באחד הוקטורים מה-codebook. במקרה הזה תמונה היא בעצם מערך באורך M של וקטורים מ-codebook (עם חשיבות לסדר כמובן!). למשל עבור M=8 (במציאות יש הרבה יותר פאצ'ים) ייצוג של תמונה יכול להיראות כך: [22, 46, 2, 11 ,98 ,17 ,9 ,78] כאשר כל איבר במערך זה הוא מספר סידורי של וקטור ייצוג מה-codebook. האימון של VQ-VAE הוא קצת טריקי כי בנוסף לפרמטרים של המקדד והמפענח צריך לאמן גם את וקטורי ה-codebook. וקטורים אלו נבחרים באמצעות פעולה לא גזירה מהפלט z של המקדד (בוחרים את הוקטור הכי קרוב z במונחי מרחק L2) שמקשה על ה-backprop. למי שמתעניין איך מתמודדים עם הסוגיה הזו ממליץ להעיף מבט ב- בבלוג מעולה של ברקלי.
המבנה של פונקציית לוס של VQ-VAE מורכב מלוס השחזור הריבועי של VAE הסטנדרטי והמרחק הריבועי בין פלט של המקדד והוקטור הקרוב מה-codebook (למעשה זה טיפה יותר מורכב עקב הפעולה הלא גזירה שתוארה קודם).
פונקציית לוס של VQ-GAN:
המאמר הנסקר בחר להחליף את לוס השחזור הריבועי בסכום של:
- הלוס הסטנדרטי של גאנים (שכמובן מצריך אימון רשת דיסקרימינטור).
- הלוס הפרספטואלי (perceptual loss).
המאמר טוען כי פונקציית הלוס המוצעת באה לתת ״טיפול שורש״ בסוגיית הכואבת של VAE: התמונות המטושטשות (יחסית לגאנים למשל) שהוא מייצר. הסיבה לכך טמונה במבנה של איבר השחזור של פונקציית הלוס הריבועית של VAE, שממזערת את השגיאה הממוצעת הגורמת לתמונה המשוחזרת להיות קרובה לתמונה המקורית, ״אך רק בממוצע״. תופעה זו, של קושי של רשתות עמוקות להתמודד עם תדרים גבוהים בקלט ובפלט, ידועה ונכתבו עליה לא מעט עבודות לאחרונה ([1], [2], [3], [4]).
הלוס הפרספטואלי:
כעת נסביר מהו הלוס הפרספטואלי Lper. המטרה של Lper היא למדוד דמיון בין הפיצ'רים של התמונה המשוחזרת לבין הפיצ'רים של התמונה המקורית. אבל אלו פיצ'רים ניקח בשביל השוואה הזו? הרי המטרה היא למדוד את ״רמת פוטוריאליסטיות״ של התמונה המשוחזרת אז הפיצ'רים צריכים לשקף את ״המאפיינים החשובים״ של התמונה המקורית. כדי להפיק פיצ'רים כאלו בדרך כלל לוקחים רשת מאומנת כמו VGG או ResNet50, ומחשבים מרחק (בד"כ L2) בין פלטים של השכבות שלהן עבור התמונה המקורית למשוחזרת.
אציין שהלוס של גאן מחושב כממוצע על פני כל הפאצ'ים של תמונה בדומה ל-PatchGAN. זה כופה על התמונה המגונרטת לא רק להיות כמה שיותר "דומה לאמיתית כמקשה אחת" אלא דורשת שדמיון זה יתקיים בכל פאץ'.
אני מאמין שסכום של שני לוסים אלו מאפשרים למפענח של VQ-VAE ליצור תמונות מרהיבות.
״למידת״ מרחב לטנטי של VQ-GAN:
אוקיי, הצלחנו להפיק ייצוג חזק מתמונה המהווה מערך של וקטורים מה-codebook (כל וקטור מיוצג ע״י המספר הסידורי שלו) כאשר כל וקטור מהווה ייצוג של פאץ' של התמונה. בשלב השני של אימון VQ-GAN המטרה היא לאמן מודל ליצירה של ייצוגים אלו (סדרות של ייצוגי פאצ'ים). כך נוכל להשתמש במודל זה לגנרוט של ייצוג לטנטי של תמונה שמוזן לאחר מכן למפענח ליצירת תמונה.
איך עושים זאת? מאחר וניתן ליצור תמונה באופן אוטורגרסיבי (פאץ' אחרי פאץ') מאמנים מפענח של הטרנספורמר (המאמר השתמש בארכיטקטורה דומה לזו של GPT2) בשביל לחזות ייצוג לטנטי (מספרו הסידורי ב-codebook) של פאץ' הבא בהינתן כל הפאצ'ים שכבר גונרטו. במשימה פאצ'ים של תמונה הם ״משחקים תפקיד של טוקנים״ של משימות של השפה הטבעית.
מעשית לאחר סיום אימון של VAE בשלב הראשון, לוקחים את כל הייצוגים הלטנטיים של התמונות מהדאטסט ומאמנים דקודר של הטרנספורמר לחזות ייצוג של פאץ' בהינתן הפאצ'ים הקודמים.
הערה: לפני תחילת שלב האימון השני, ״מקפיאים״ את כל הפרמטרים של המקדד, המפענח ואת ה-codebook.
״תיבול״ של inductive bias:
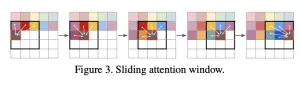
רגע, אבל מה עם התבלין מסוג inductive bias שהבטחתי קודם לכן? המחברים מצאו כי שימוש בפאצ'ים גדולים מ-16×16 פוגע בביצועים של המודל. מצד שני עקב משאבי החישוב המוגבלים שעמדו לרשותם, הם לא הצליחו לאמן טרנספורמר עבור יותר מ-256 פאצ'ים. איך יוצאים מהמצב הזה ומגנרטים תמונות גדולות יותר מ-256×256? פשוט משתמשים רק בפאצ'ים הקרובים לפאץ' הנחזה – והנה קיבלתם ה-inductive bias המובטח 🙂
סיכום קצר של שלבי אימון VQ-GAN:
- מאמנים VQ-VAE כאשר פונקצית הלוס היא שילוב הלוס הסטנדרטי של גאן והלוס הפרספטואלי (perceptual loss).
- מקפיאים את כל הפרמטרים של כל הרשתות שאומנו בשלב הראשון.
- לוקחים את כל הייצוגים הלטנטיים של התמונות מהדאטהסט
- מאמנים מפענח של הטרנספורמר לחיזוי הוקטורים הלטנטיים מהשלב הקודם
איך מגנרטים תמונות: יוצרים ייצוג לטנטי של תמונה באמצעות מפענח מאומן של הטרנספורמר ומעבירים ייצוג זה דרך המפענח של VAE שאומן בשלב הראשון ונותר ללא שינוי מאז.
הישגי מאמר:
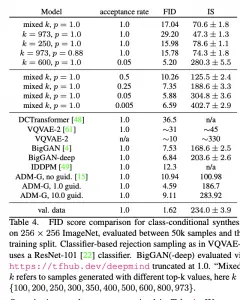
המחברים הראו שיפור מבחינת (Frechet Inception Distance (FID ו- (Inception Score (IS מול מודלים גנרטיביים חזקים עבור כמה דומיינים ורזולוציות.

נ.ב.
ממש אהבתי את המאמר כי הוא משלב גישות מאוד מעניינות בלמידה עמוקה: VQ-VAE, GAN וטרנספורמרים וגם מנצל את ה-inductive bias הקיים בדומיין הויזואלי. מומלץ בחום רב!
מילות תודה:
ברצוני להודות לעדו בן-יאיר על עזרתו בהכנת סקירה זו.
#deepnightlearners
הפוסט נכתב על ידי מיכאל (מייק) ארליכסון, PhD, Michael Erlihson.
מיכאל עובד בחברת הסייבר Salt Security בתור Principal Data Scientist. מיכאל חוקר ופועל בתחום הלמידה העמוקה, ולצד זאת מרצה ומנגיש את החומרים המדעיים לקהל הרחב.


