הסקירה כפולה: Make-A-Video ו- Dreamix

סקירה זו היא חלק מפינה קבועה בה אני סוקר מאמרים חשובים בתחום ה-ML/DL, וכותב גרסה פשוטה וברורה יותר שלהם בעברית. במידה ותרצו לקרוא את המאמרים הנוספים שסיכמתי, אתם מוזמנים לבדוק את העמוד שמרכז אותם תחת השם deepnightlearners.
לילה טוב חברים, היום אנחנו שוב בפינתנו deepnightlearners עם סקירה של שני מאמרים בתחום הלמידה העמוקה בו זמנית. בחרנו לסקירה את המאמרים הנקראים:
Make-A-Video: Text-to-Video Generation without Text-Video Data
ו-
Dreamix: Video Diffusion Models are General Video Editors
פינת הסוקר:
המלצת קריאה ממייק: מומלץ לאלו העוסקים בגנרוט ובעריכה של סרטוני וידאו
בהירות כתיבה: בינונית ל- Make-A-Video וטובה ב-Dreamix
ידע מוקדם:
- הבנת יסודות של DDPM (כולל איך מגנרטים וידאו מטקסט)
- עקרונות של גנרוט של סרטוני וידאו
יישומים פרקטיים:
- גנרוט ועריכה של וידאו מטקסט או מתמונה/ות נתונה/ות
פרטי מאמר:
לינקים למאמרים: זמין להורדה1, זמין להורדה 2.
לינק לקוד: לא מצאתי לשניהם
פורסם בתאריך: 29.09.222 ו-02.02.2023, בארקיב.
הוצגו בכנס: —.
תחומי מאמר:
- מודלים גנרטיביים
- מודלי דיפוזיה (DDPM)
- גנרוט וידאו מטקסט
- כיול מודלי דיפוזיה מאומנים
כלים מתמטיים, מושגים וסימונים:
- מודלי דיפוזיה (Denoising Diffusion Probabilistic Models- DDPM)
- טרנספורמרים
- CLIP
- Imagen
- DreamBooth
מבוא:
זוהי הסקירה הראשונה ב-deepnightlearners שבה אסקור יותר ממאמר אחד. Make-A-Video הוא מאמר די עתיק (יצא לפני 9 חודשים) הוא אחד המאמרים הראשונים בנושא המרתק של Text2Video. המאמר השני Dreamix משדרג את היכולות שפותחו ב-Make-A-Video ומציע יכולות חדשות כמו עריכה של וידאו וגנרוט של וידאו מכמה תמונות.
נתחיל מלסקור את Make-A-Video שמטרתו היא לקחת שיטות ליצירת תמונות מתיאור טקסטואלי (DALLE-2, Imagen, Stable Diffusion וכדומה) ולהתאים אותן ליצירת סרטוני וידאו. למעשה המאמר מקנה למודל Text2Image יכולת ליצור סדרה קוהרנטית של תמונות (פריימים) במילים אחרות סרטון וידאו.
מודלי Text2Image מבוססי דיפוזיה:
נתחיל מהסבר קצר על איך עובדות השיטות לגנרוט דאטה מטקסט (Text2Image) כמו אלו שהזכרנו קודם. מודלים אלו מבוססים כולם על מודלי דיפוזיה הסתברותיים (DDPM).
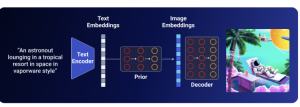
איור 1: אבני בניין של Stable Diffusion
רוב מודלי Text2Image מורכבים מהחלקים הבאים:
- מקודד של טקסט: (Text Encoder): מפיק שיכון (embedding) של תיאור התמונה. בדרך כלל לוקחים מודל שפה ענקי (LLM) כמו T5 או CLIP ומשתמשים בו כמו שהוא או מכיילים במהלך אימון. המאמר משתמש במודל CLIP מאומן לחישוב ייצוג(=שיכון) של הטקסט ושל התמונה.
- מודל הממפה שיכון של טקסט לשיכון של התמונה, Prior. מודל זה הינו אופציונלי ולמשל Imagen לא משתמש בו. Prior בדרך כלל מבוסס על מודלי דיפוזיה (כמו ב-DallE-2 ו-Stable Diffusion) עם ארכיטקטורת U-Net. דרך אגב DallE-2 בדקו ארכיטקטורה אוטורגרסיבית אך לטענת המחברים זה עבד פחות טוב
- מפענח (decoder): בונה את התמונה מהשיכון שלה. מודל זה יכול להיות מבוסס על מודל דיפוזיה (כמו ב-DallE-2 ו-Imagen) או סתם רשת נוירונים כמו ב-Stable Diffusion. שימו לב שהדקודר מבוסס מהווה מה שנקרא cascaded model, שמורכב מכמה מודלי דיפוזיה המבצעים דגימת יתר (upsampling) כל הדרך לרזולוציה הנדרשת.

איור 2: Imagen – מודל דיפוזיה cascaded
תקציר מאמר Make-A-Video:
כאמור Make-A-Video הינו שכלול של מודלי Text2Image המאפשר לגנרט וידאו מהתיאור הטקסטואלי. הבעיה המהותית ביותר באימון מודל כזה היא היעדר דאטהסטים גדולים וזמינים של סרטוני וידאו באיכות גבוהה בעלי תיאור טקסטואלי. המחברים ״עוקפים״ בעיה זו ומאמנים את המודל שלהם קודם כל על הדאטהסט המכיל תמונות עם כותרת ולאחר מכן מכיילים אותו עם סרטוני וידאו לא מתויגים (ללא תאור).
ארכיטקטורת Make-A-Video די מזכירה את מה שתואר בסעיף הקודם. השוני המהותי היא החלפה של קונבולוציות דו-מימדיות (2d) רגילות שהיו ב- UNet (עם attention) שכיכבו ב- Stable Diffusion (ראה איור 3), בקונוולוציות 3d פריקות (separable). במאמר קונבולוציות אלו נקראות spatial-temporal.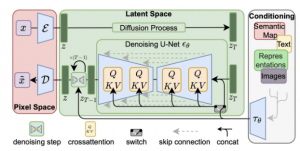
איור 3: UNet עם שכבות ה-attention
המימד הנוסף שהתווסף לשכבות הקונבולוציה הוא באופן לא מפתיע מימד הזמן. שכבות אלו מאומנות (מכוילות) לשמירת הקוהרנטיות והשטף הרציף של הפריימים (ראה איור 4).
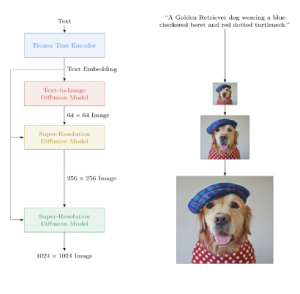
גנרוט וידאו עם Make-A-Video מורכב מכמה שלבים:
- יצירת 16 פריימים בגודל 64×64 מהטקסט.
- ביצועי דגימת יתר למספר פריימים לשניה גבוה יותר תוך שמירה על הרזולוציה של כל פריים.
- שלב SRl: דגימת יתר במרחב הפיקסלים ו/או במרחב הזמן (=מעלים מספר פריימים לשניה).
- שלב SRh: מגדילים רק את רזולוציית הפריימים תוך שמירה על אותו fps (אחרת זה יוצא כבד מדי מבחינה חישובית לאמן את זה). בסוף התהליך מקבלים וידאו ברזולוציה 768×768 באורך של כמה שניות (המחברים מבצעים downsampling ל-512×512 בטענה שזה מוריד רעשים של תדרים גבוהים שיצאו לא טוב ברזולוציה 768×768).

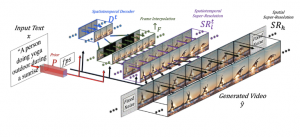
איור 4: דיאגרמה כללית של Make-A-Video
הערה: איור 4 הינו לגמרי ברור אך ההסבר המעמיק מגיע כבר בפרק הבא.
איך מאמנים Make-A-Video:
האימון של המודל מכיל 3 שלבים עיקריים:
- אימון של רשת Prior המקבלת ייצוג (שיכון) של טקסט וממפה אותו לשיכון של תמונה. מודל זה מאומן על דאטהסט של תמונות עם כותרת כאשר השיכון של טקסט והשיכון של תמונה מחושבים עם המודלים המאומנים של CLIP (לא ברור אם מודלים CLIP מכויילים או מוקפאים בשלב הזה). הפריור ממומש כמודל דיפוזיה מותנה (conditional diffusion model) המקבל שני פלטים: השיכון של CLIP עבור הטקסט וגם השיכונים של הטוקנים (BPE). לאחר מכן ה-Prior מוקפא ולא מכויל יותר.
- מאמנים את הדקודר (היוצר תמונה ברזולוציה הנמוכה ביותר 64×64) ושני המודלים של upsampling על דאטהסט המכיל תמונות בלבד (ראה איור 2). נציין כי הקלט לדקודר מחושב עם CLIP (מוקפא למרות שהמאמר לא מציין זאת במפורש). בשלבים אלו מודל מאומן ללא שכבות קונבולוציה עתיות (temporal convolution) אלא כמו מודל רגיל לגנרוט של תמונות מטקסט. כל המודלים הינם מודלי דיפוזיה מותנים. הדקודר מקבל את הפלט של CLIP (השיכון של התמונה) כקלט והקלטים לשני מודלים של super-resolution הם הפלטים של השלבים הקודמים להם.
- מוסיפים למודל, המאומן בשלב הקודם, קונבולוציות עתיות בדקודר ומכיילים את המודל עם קטעי וידאו בלבד (ללא כותרת). שכבות הקונבולוציה המרחביות מאותחלות עם המשקלים מהשלב הקודם והקונבולוציות העיתיות מאותחלים עם וקטורי one-hot ששקול ללא לעשות שום אינטרפולציה בציר הזמן. המודל מייצר 16 תמונות לכותרת נתונה ולאחר מכן מבצעים upsampling (כלומר סוג של smoothing) לתמונות אלו כדי להפוך אותם לוידאו קוהרנטי. מאמנים באמצעות מיסוך של פריימים מסוימים בוידאו כאשר המודל מתבקש לנחש את הפריימים הממוסכים.
תקציר מאמר Dreamix:
המאמר מציע מודל המסוגל לבצע מספר פעולות עם וידאו:
- עריכת וידאו בהתאם לתיאור טקסטואלי.


- יצירת וידאו מתמונה בודדת ותיאור טקסטואלי (המתארת פעולה בוידאו)


- יצירת וידאו מכמה (מספר קטן) של תמונות ותיאור טקסטואלי.


הכותבים משתמשים במודל שהוצע במאמר Imagen-Video כמודל בסיס ומכיילים אותו כדי לאפשר ביצוע של הפעולות אלו. עקרונות המודל של Imagen-Video הם די דומים ל-Make-A-Video שאותו תיארנו בפרקים הקודמים. שני מודלי אלו מבוססים על אותם העקרונות אך יש להם שלושה הבדלים עיקריים:
- Imagen-Video משתמש במודל T5-XXL לבניית שיכון של פרומפט (Make-A-Video משתמש ב- CLIP).
- Imagen-Video לא משתמש ברשת Prior ההופכת שיכון של פרומפט לשיכון של תמונה (וידאו למעשה).
- Imagen-Video משתמש ב-3 מודלים של upsampling מרחבי (רזולוציה) ועוד 3 ל-upsampling בציר הזמן (בסך הכל 6 מודלים) ולא בשניים כמו Make-A-Video.
Dreamix לוקח את המודל של Imagen-Video ומשתמש בו כדי לערוך וידאו וגם כדי ליצור וידאו מתמונה בודדת ותיאור. איך זה נעשה? למשל למשימת עריכת וידאו, קודם כל מוסיפים רעש לווידאו, המתאים לאיטרציה t (ראה הערה מתחת לפסקה זו) של התהליך הקדמי של DDPM ומורידים לו רזולוציה מרחבית וגם קצב הפריימים בשניה. לאחר מכן Imagen-Video משחזר ממנו את הסרטון המקורי כאשר אחד הקלטים הוא הפרומפט. כדי ליצור וידאו מתמונה בודדת ותיאור פעולה, הכותבים של Dreamix משכפלים את התמונה כמה פעמים. לאחר מכן ״מכניסים לתמונות אלו קצת דינמיקה״ על ידי הפעלה של טרנספורמציות המדמות תנועה רציפה (שינוי מיקום, כיוון וכדומה) של המצלמה. לאחר מכן מוסיפים רעש ומעבירים דרך Imagen-Video ליצירה של וידאו ברזולוציה הרצויה.
הערה: למעשה t זה לא מספר האיטרציה אלא מספר ממשי בין 0 ל-1 כאשר 0 מסמן דוגמא נקיה ללא תוספת רעש ו-1 מתאים לרעש גאוסי טהור (האיטרציה האחרונה של התהליך הקדמי).
הגישה הנאיבית הזו, שלא דורשת כיול של Imagen-Video לא הצליחה ליצור וידאו באיכות מספיק טובה עבור משימת עריכת הוידאו. הסיבה לכך לדעת המחברים היא אי יכולת לשמור על התכונות האינהרנטיות של הוידאו המקורי. כדי להתגבר על בעיה זו, המחברים השתמשו בשיטה שהוצעה ב-DreamBooth (ד״א חוקרים ישראלים נטלו חלק גם במחקר הזה). הכותבים של DreamBooth פיתחו שיטה לכייל מודל דיפוזיה Text2Image מאומן כך שיוכל לגנרט תמונות עם אובייקט נתון (נגיד כלב מסוים או אגרטל, ראה איור למטה) – תהליך זה נקרא personalization.
 איור 5: personalization עם DreamBooth
איור 5: personalization עם DreamBooth
ב-DreamBooth הכיול זה מתבצע באופן הבא:
- בוחרים ״שם״ לאובייקט באמצעות קידודו עם טוקנים נדירים, כלומר טוקנים בעלי שכיחות נמוכה (ראה הערה).
- מכיילים מודל עם תמונות של האובייקט כאשר הפרומפט מכיל את ״השם״ הנבחר של האובייקט (in a doghouse "#$" ) כאשר "#$" הוא קידוד האובייקט.
הערה: בחירה של טוקנים רגילים לקידוד האובייקט ולא קומבינציות נדירות של טוקנים רגילים (כמו ״xzy30sbs4a״) מנומקת במאמר (DreamBooth) באופן הבא: טוקנים רגילים משוכנים (embedded) בנפרד ע"י הטוקנייזר ולכל אחד מהם עשוי להיות פריור חזק. וכיול המודל יכול לשנות אותם וזה עלול לעוות את המבנה של המרחב הלטנטי של הטקסט והיישור (alignment) שלו עם המרחב הלטנטי של התמונות.
המחברים של Dreamix משתמשים בגישה זו ומכיילים את Make-A-Video עם הוידאו המקורי. כאן הכיול משלב את שני היעדים הבאים:
- ״מלמדים״ את Make-A-Video לשחזר את הוידאו עצמו מהגרסאות המורעשות שלו.
- לכל פריים בודד ״מלמדים״ את המודל לשחזר כל פריים נקי מהפריימים המורעשים אחד אחד.
שני כיולים אלו מתבצעים פעם אחת לכל וידאו הנערך ולאחר מכן ניתן לערוך אותו כרצוננו. למעשה זה שלב מקדים לפני עריכה של וידאו נתון.
הערה: לא ברור איך בוחרים את הטוקנים הנדירים לשלבים האלו (האם פריימים של הוידאו וידאו עצמו מקודד עם אותם טוקנים נדירים).
דגימה מ-Dreamix:
כמו ברוב המוחלט של מודלי הדיפוזיה הדגימה בהם מתבצעת באמצעות שיטת DDIM. שיטה זו מאפשרת תהליך מהיר יותר (פחות איטרציות) של הסרת הרעש (denoising=backward process) שמזרז גנרוט של דאטה. האצה זו מתאפשרת כאשר משנים את התהליך הקדמי להיות לא מרקובי (xt תלוי לא רק ב xt-1 אלא גם ב-x0). המאמר הזה לדעתי מקבל הרבה פחות תשומת לב ממה שמגיע לו ואני מתכנן לסקור אותו באחת הסקירות הבאות.
נ.ב.
בסקירה זו סקרנו שני מאמרים המציעים מודלים text2video. המאמר הראשון מציע שיטה לגנרט וידאו מטקסט, כאשר המאמר השני משכלל יכולות אלו ובונה מודל המסוגל לערוך וידאו בהתאם לתיאור הטקסטואלי וגם ליצור וידאו מסדרה של תמונות.
ברצוני להודות לשחר גיגי על ההגה (תודה!!).
#deepnightlearners
הפוסט נכתב על ידי מיכאל (מייק) ארליכסון, PhD, Michael Erlihson.
מיכאל עובד בחברת הסייבר Salt Security בתור Principal Data Scientist. מיכאל חוקר ופועל בתחום הלמידה העמוקה, ולצד זאת מרצה ומנגיש את החומרים המדעיים לקהל הרחב.


