לחזות את המשרה הבאה שלכם: הצצה למרכז הפיתוח של חברת ZipRecruiter בישראל

מרבית המאמרים והכתבות בבלוג עוסקים ב-Machine Learning בהיבטים הקשורים לראייה ממוחשבת או עיבוד שפה טבעית, ולעתים נדירות אנו שומעים שימושים יצירתיים בתחומי פעילות שונים. מידי פעם אני מנסה להעניק הצצה לזוויות נוספות של הטכנולוגיה ולחשוף כיצד Machine Learning יכול לסייע במגוון רחב של תחומים.
אחד התחומים שמתחיל לאמץ לחיקו טכנולוגיות מתקדמות הוא תחום גיוס העבודה (HR), שרותם לאחרונה אלגוריתמים חכמים בכדי ליצור מודלים שיחזו בדיוק רב את מידת ההתאמה בין חברה מגייסת לבין מועמד פוטנציאלי. בשיטה "הישנה" מדובר עדיין על אתגר משמעותי שמצריך, משני הצדדים, להשקיע זמן לא מבוטל בכדי למצוא התאמה מלאה. בסופו של יום, כולנו היינו מעדיפים פשוט למצוא ישירות את החברות המתאימות לנו ביותר – ובאותה הנשימה, החברות עצמן היו מעדיפות לקצר באופן משמעותי את התהליך ולקלוט את העובד הרלוונטי כמה שיותר מהר.
בכדי ללמוד עוד על התחום ועל הדרך בה אלגוריתמים מעולם ה-Machine Learning מצליחים לחזות התאמות מסוג זה, ערכתי ראיון עם אבי גולן מחברת ZipRecruiter האמריקאית, בה הוא משמש כמנהל הפעילות של החברה בישראל וסגן נשיא להנדסה בחברה העולמית.

לפני שאנחנו צוללים לטכנולוגיה, קצת רקע: ZipRecruiter, אשר נוסדה בשנת 2010, זיהתה את האתגר הנ"ל ובעצם מספקת מענה לצורך זה באמצעות Marketplace פרי פיתוחה. השירות של החברה מזהה התאמות בין מחפשי עבודה למעסיקים ואף מחבר ביניהם בצורה אקטיבית. בשנת 2014 השלימה החברה סבב גיוס הון ראשון בסכום של 63 מיליון דולר, בהובלת Institutional Venture Partners. כיום ZipRecruiter מעסיקה יותר מ-600 עובדים בשלושה סניפים בסנטה מוניקה-קליפורניה ובטמפה-אריזונה, ומתמקדת אסטרטגית בשוקי העבודה של ארה"ב, קנדה ובריטניה.
לשאלתי, גולן מסביר על הקשר בין ZipRecruiter לישראל: "בשנת 2015 החברה הקימה בתל אביב את מרכז הפיתוח הראשון והיחיד שלה מחוץ לגבולות ארה"ב, במטרה למקסם את החדשנות הטכנולוגית שלה ב"סיליקון ואדי" הישראלי. ראשי החברה מעידים בעצמם שזו חברה חצי ישראלית, לאור הנוכחות המסיבית של ישראלים בכירים במטה שלנו בסנטה מוניקה, החל מתפקידי הנדסה ופיתוח תוכנה ועד לשיווק וניהול."
מאז שנת 2015 מרכז הפיתוח הישראלי אמון על פיתוח מודלים שונים שיסייעו לחברה לחזות התאמות במגוון רחב של תחומים הקשורים לגיוס עובדים. "אנו אחראים על מציאת ההתאמה המושלמת בין המועמד לתפקיד שמתאים לו ביותר. זה שירות שמיועד גם למחפשי עבודה וגם עבור המעסיקים. עיקר הפוקוס שלנו נתון לפיצוח האתגר הזה מכמה זוויות שונות. החל ביצירת תשתית שתתמוך בתהליך הניתוח, ועד לפרויקטי פיתוח הנוגעים לזיהוי התאמות ספציפיות." פירט גולן.
כמו כן, גולן הסביר כי המרכז הישראלי פועל רבות בהיבטים הקשורים לניתוח טקסט והבנה של אופי המועמד על פי פרטי מידע שונים אודותיו. "הפרויקטים בתחום התשתית כוללים title classification, יצירת טקסונומיה של כישורים, חיזוי שכר וחילוץ מידע מובנה מטקסט חופשי כמו מודעות דרושים וקורות חיים. הפרויקטים שאנו מפתחים לזיהוי התאמות (matching), אשר מסתמכים על פרויקטי התשתית שפיתחנו, כוללים איתור מועמדים מתאימים למודעות חדשות שרק נכנסו למערכת, איתור הצעות עבודה למשרות הדומות למשרה ספציפית וזיהוי מחפשי עבודה הדומים למשתמש נתון."
בכדי להתמודד עם האתגרים השונים, מרכז הפיתוח הישראלי עמל על שילוב טכניקות רבות מעולם ה-Machine Learning, אשר הצליחו לסייע לו להגיע לאחוזי חיזוי גבוהים למדי. גולן הרחיב על הנושא וציין כי: "רוב הפיתוחים שלנו מבוססים על Machine Learning – בנינו תשתית ב-Python מעל TensorFlow, שמאפשרת לנו להטמיע מודלים חדשים ב-Production במהירות וביעילות."
מה שמרתק בתהליך כולו הוא שחברת ZipRecruiter מפיקה ערך מכל אינטראקציה של המשתמש עם המערכת שלהם ועל בסיס מידע זה מאמנת את המודלים שלה. החברה מנסה לחזות גם תהליכים עמוקים יותר מאשר רק התאמה למשרה הבאה, ואפילו מנסה לחזות את השכר של מועמד כזה או אחר. בכל אותן משימות פיתחה החברה מודלים שונים שמסייעים לה ביחד להרכיב את התמונה המלאה ולשדך בין עובדים ומעסיקים.
גולן התייחס לנקודה זו והסביר כיצד הדברים מתבצעים בפועל: "אנו מפתחים כעת אלגוריתם מורכב, המתבסס על Deep Learning בשילוב עם collaborative filtering, שמטרתו לזהות מועמדים המתאימים להצעות עבודה חדשות שנכנסו למערכת. גם זיהוי מועמדים דומים ומשרות דומות הם פרויקטים שמבוססים על טכניקת Machine Learning, כמו גם חיזוי שכר. פרויקט מעניין נוסף שפיתחנו יודע לחזות את הצעד הבא במסלול הקריירה של המשתמש."
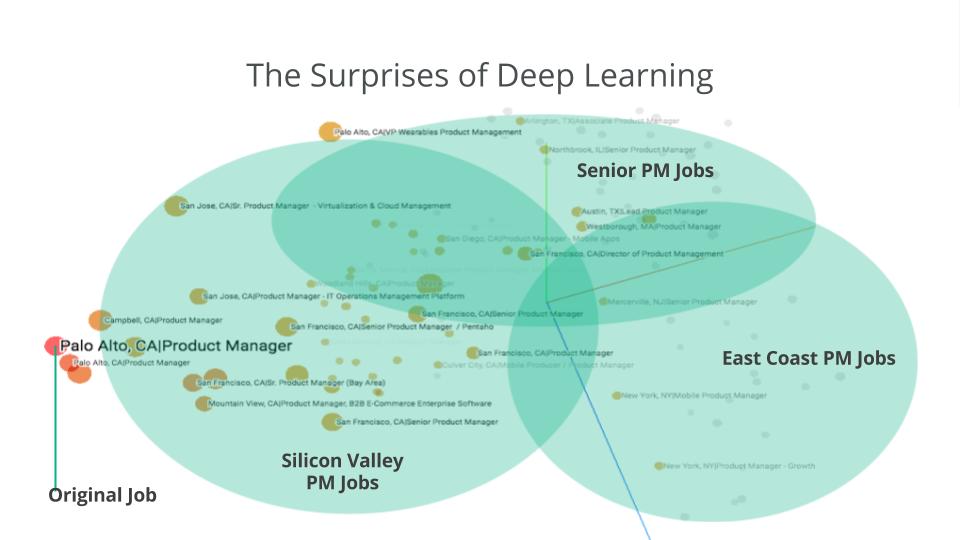
לפתח מודלים שכאלה, שלא נדבר על לגרום להם לפעול בשטח, זו לא משימה פשוטה. לחיפוש עבודה יש השלכות רבות בעולם האמיתי ומספר רב של טעויות יורידו את רמת האמון הן אצל המעסיקים והן אצל העובדים. מרכז הפיתוח הישראלי נתקל בלא מעט אתגרים במהלך שנות הפעילות שלו וכעת גולן חושף בפנינו כמה טכניקות שסייעו להם להתגבר על אותם האתגרים. "רוב המידע שיש לנו על מחפשי העבודה מגיע מפעולות בהיסטוריה התעסוקתית שלו, ואנו לומדים כל הזמן איך לחזות בצורה טובה יותר את הצעדים הבאים שלו בהסתמך על צעדיו עד כה. שימוש בכל המידע שבידינו לאימון הרשת יכול ליצור עיוות בתהליך הלמידה, כי יתכן מצב שבו אנחנו משתמשים בפעולות עתידיות של מחפש העבודה לחיזוי פעולה שקרתה לפניהן. בזמן אמת מידע כזה לא יהיה זמין, ולכן הלמידה לא מדמה מצב אמת. כדי לפתור את הבעיה הזו, בנינו תשתית שמייצרת את המידע הזמין ללמידה בשימוש בחלון נע, תוך הדחקת פעילויות עתידיות. בנוסף לכך חלק מהפיצ'רים הכילו מידע יחסית דליל – לדוגמה בחלק של הכישורים והטייטלים (תיאור תפקיד) של העובד. כדי לייעל את יכולת הלמידה שלנו מהתכונות הללו, יצרנו ייצוגים בדידים עבור תכונות שונות לפני הכנסתן לרשת, תוך שימוש באלגוריתם "item2vec" המבוסס על אותו רעיון כמו "word2vec"."
בעוד ששני האתגרים הראשונים היו סביב סט הפעולות של המשתמש או הטקסט אותו הזין, ZipRecruiter צריכה להתמודד עם אתגר משמעותי נוסף: מיקום המשתמש. גולן פירט כי הם התחילו לתקוף את הבעיה בצורה סטנדרטית, אך לבסוף נאלצו לפתח טכניקה חדשה שתחשב בצורה נאמנה יותר את החשיבות של המרחק הגאוגרפי של כל מועמד.
"אתגר נוסף שאתו התמודדנו, היה איך להציג את פיצ'ר המיקום. באמצעות קואורדינטות מדויקות, הפיצ'ר יצא דליל מדי בנתונים, ושימוש בעיר היה מספק פתרון רק עבור ערים שנדגמו מספיק פעמים במהלך ה-training – מה שמשאיר ערים קטנות יותר מחוץ לתמונה. כמו כן, חלוקה שרירותית של המפה לא תשקף את המציאות שבה אנשים מערים קטנות יהיו ככל הנראה מוכנים לנסוע רחוק יותר מאשר אנשים שחיים בערים גדולות עם הרבה הזדמנויות תעסוקה. לבסוף החלטנו ליצור ייצוגי מיקום על ידי חלוקה של המפה לאריחים בגודל משתנה, כאשר גודל האריח נקבע לפי צפיפות האוכלוסייה – ככל שאזור צפוף יותר כך האריח שלו קטן יותר."
אין ספק שעל הנייר הצליחה ZipRecruiter להגיע לפיתוחים מרשימים למדי, אך האם בפועל מצליחה החברה להגיע לאחוזי שביעות רצון גבוהים בקרב משתמשיה? על פי גולן, התשובה היא כן, והוא מציין כי הם אף מתעלים על לא מעט פתרונות אחרים בשוק.
"אחד מכול שבעה מחפשי עבודה שזיהינו כמתאים אכן מגיש מועמדות למשרה. בנוסף, הדו"חות שלנו מעידים כי רמת שביעות הרצון של המעסיקים מהמועמדים שאנו מפנים אליהם (על פי שיעור ה-thumb up) גבוה בכ-20% משיעור שביעות הרצון הממוצע. מאחר שאנו מתבססים על פעולות של מספר רב של מחפשי עבודה, אנו מסוגלים להבין ולהגדיר טוב יותר מה מחפש כל אחד מהם, ולפיכך גם להרחיב את החיפוש ולהציע אפשרויות נוספות שהמועמד אפילו לא היה מתייחס אליהן. האלגוריתם שלנו יודע גם לסנן תוצאות לא רלוונטיות ומאחר שאנו יודעים לחזות מסלולי קריירה אפשריים לעתיד, אנו מסייעים למחפשי העבודה להתקדם אל עבר מה שיכול להיות התפקיד הבא שלהם. יש ל-ZipRecruiter כמויות עצומות של מידע ונתונים. כרגע יש אצלנו יותר מ-7 מיליון הצעות עבודה ויותר מ-12 מיליון מחפשי עבודה פעילים – המגיעים ממגוון ענפי תעשייה ומקצועות שונים בכל רחבי ארה"ב. זוהי החוזקה העיקרית שלנו, והאלגוריתם שלנו יודע למנף זאת בצורה המיטבית. הפרויקט המשמעותי ביותר שאנו עובדים עליו הוא כיצד לזהות את המועמדים המתאימים ביותר עבור משרה חדשה שנכנסת למערכת. הודות לשימוש באלגוריתם שמשלב collaborative filtering עם מודל מבוסס תוכן, אנו מנצלים את כוח הנתונים שיש בידינו ומחילים אותו לניתוח משרות ומועמדים שאין לנו היסטוריה לגביהם."
לסיכום, נראה כי Machine Learning מצליח לחולל מהפכה לא קטנה גם בעולם ה-HR ומצליח לפשט תהליך שלעיתים יכול להיות מעיק וממושך. חשוב לציין כי תהליכי גיוס מהירים יותר יכולים לסייע לחברות לצמוח בצורה מהירה וטובה יותר, אך לצד זאת תהליכים אלו יכולים לסייע גם למשק כולו לשגשג ואף להוריד את אחוזי האבטלה.
הסנדלר לא הולך יחף, ומרכז הפיתוח המקומי של ZipRecruiter נמצא בתהליך צמיחה מואץ ומגייס עבורו עשרות עובדים. בימים אלה עוברים העובדים למשרדים חדשים במרכז תל אביב וקוראים למועמדים רלוונטיים לשלוח קורות חיים.
מוזמנים לבדוק משרות רלוונטיות באתר החברה בקישור בא.



