Vision Language Models – שילוב של טקסט ותמונה באותו מודל

חלק א' – מבוא
אחד הנושאים הבולטים בתחום למידה עמוקה בשנה האחרונה הוא Multiple Modalities – שילוב דאטה ממספר דומיינים באותו מודל, כמו למשל מודל המסוגל לעבד יחד וידאו ואודיו, או לחילופין מודל היודע להפוך תמונה לטקסט ולהיפך. כמובן שתחום זה אינו חדש במחקר, אך לאחרונה יש בו חידושים טכנולוגיים פורצי דרך יחד עם תוצאות מדהימות במגוון רחב של משימות. מעבר לעובדה שיש יותר ויותר אפליקציות המשלבות דאטה ממספר דומיינים, מה שמגביר את ההתעניינות בתחום הן מבחינה מחקרית והן מבחינת פיתוח, נראה שיש לפופולריות הזו סיבה מהותית יותר. מודל המשלב בתוכו יכולת לעבד ולשלב דאטה מדומיינים שונים מצליח "להבין" יותר לעומק את המבנה הדאטה שהוא מקבל ועקב כך הביצועים שלו טובים יותר. מחקרים חדשים המתבססים על שילוב של דומיינים מראים תפיסה טבעית יותר של הקלט, מה שמאפשר למודל ללמוד בצורה יותר איכותית. בכתבה זו נסקור אחד הרעיונות המרכזיים לאימון מודלים המשלבים דאטה טקסטואלי וויזואלי. אמנם גישה זו הוצעה כבר בעבר אך היא שוכללה בצורה משמעותית בשנה האחרונה ולא מעט מאמרים עכשוויים מבוססים עליה. נעבור בקצרה על כמה עבודות מרכזיות המציעות שיטות לבניית ייצוג של דאטה מולטימודלי המורכב מטקסט ותמונות.
Disclaimer: המטרה של הסקירה היא לא להכנס לפרטים של מאמרים ספציפיים אלא להביט על רעיון מסוים מכמה היבטים. יתכן וחלק מהמאמרים המוזכרים אינם מתוארים בצורה הכי מפורטת ומדויקת, מכיוון שהמגמה היא לתאר את עיקרי הדברים וכיווני מחשבה שנגזרים מהם.
אז… איך ניתן לשלב עיבוד תמונה יחד עם ניתוח טקסט?
חלק ב' – CLIP
נתחיל עם מאמר יחסית חדש מלפני בערך שנה: CLIP: Connecting Text and Images. נסתפק בתיאור יחסית כללי של הרעיונות המרכזיים העולים מתוך המאמר.
כשאנו מאמנים מודל לבצע משימה מסוימת, למשל לסווג חיות מסוגים מסוימים, המודל מתמקד במשימה אחת – ללמוד להבחין בין החיות השייכות לסוגים שונים. לחילופין אם המודל אומן לזהות מיקום של אובייקטים – אז הוא מתמקד רק בלמצוא איפה האובייקטים נמצאים בתמונה. התמקדות במשימה ספציפית באימון יכולה לספק מודל המבצע את המשימה הזו בצורה כמעט מיטבית, אך עם זאת הוא (המודל) אינו מסוגל לבצע משימות דומות לדאטה מדומיין קרוב. למשל – מסווג שאומן להבחין בין מספר מחלקות, לא יצליח לסווג נכון דוגמאות ממחלקות שהוא לא ראה במהלך האימון. בעיה זו נקראת "zero-shot" ועוסקים בו אימון מודלים המסוגלים להתמודד עם אובייקטים (קטגוריות) שכלל לא נראו במהלך האימון. ניתן להסתכל על האתגר של zero shot בשתי דרכים: בפן הטכני, מובן שמודל לא יוכל לזהות אובייקטים שהוא לא ראה בזמן האימון, שהרי אין לו מושג מה הם. בפן היותר מהותי, חוסר היכולת לבצע זאת נובע בבעיה מובנית שיש בלמידה שמתמקדת בהיבט ספציפי של הדאטה. למידה כזו מתייחסת רק לחלק מהמאפיינים הסמנטיים של התמונה, אך היא מתעלמת מהיתר – אלו שאינה תורמים לה. לכן למשל, אם נאמן מסווג להבחין בין כלב לחתול, כל פריט מידע שלא יתרום להבחנה זו לא יעניין את המודל, גם אם הוא יכול למשל לסייע בהבחנה בין כלב לפיל.
יש לא מעט עבודות בתחום zero-shot, אך רובן מתמקדות בשאלה "כיצד לסווג קטגוריות שהמודל לא ראה באימון" ופחות בבעיה הכללית יותר של הלמידה החלקית שמתרחשת כאשר מתמקדים במשימה ספציפית (כלומר – שהמודל מתרכז אך ורק בדברים החשובים לו למשימה אותה הוא לומד, מה שמונע ממנו לבצע גם משימות אחרות). העבודה הזו באה לתת מענה לבעיה הכללית יותר, והגישה שהיא מציעה מאוד אלגנטית ואינטואיטיבית.
במקום להתמקד במשימה ספציפית – למשל סיווג אובייקט בתמונה או זיהוי המיקום שלו – ננסה להבין בצורה יותר מופשטת את המאפיינים החשובים תמונה. איך נעשה את זה? נאמן מודל שידע לתאר בצורה הטובה ביותר את התוכן הסמנטי של התמונה. בכדי לעשות זאת לקחו 400 מיליון תמונות שיש עליהן תיוג בצורה של תיאור מילולי, ואימנו מודל שידע לשייך תמונה לתיאור. עכשיו נשאלת השאלה – איך נוכל לשייך תמונה לטקסט, הרי הם דומיינים לא דומים ומיוצגים בצורה שונה לחלוטין? המאמר מציע לבנות עבורם מרחב משותף, בו לתמונה והתיאור שלה יש את אותו ייצוג. כלומר, מייצרים מנגנון אמבדינג (באמצעות רשת נוירונים) שמתאר כל מקטע טקסט כנקודה במרחב רב-ממדי כאשר מנגנון דומה יודע למפות תמונה לנקודה באותו מרחב רב-ממדי. בעולם של טקסט זה משהו בסיסי – כל משימת עיבוד שפה מתבססת על אמבדינג של טוקנים במרחב כלשהו הניתן לתיאור מתמטי יחסית פשוט, והחידוש פה הוא ההוספה של שיכון התמונות באותו מרחב. יש להעיר שהרעיון לבצע את השיכון לאותו מרחב כבר הוצע בעבר, אך פה הוא שודרג באופן ניכר, בעיקר באמצעות אופן הלמידה והשימוש ב-Contrastive Learning.
הרעיון של Contrastive Learning (למידה-ניגודית), מגיע בעיקר מהתחום של למידה בה אין תיוגים (Unsupervised Learning). נניח ואנו רוצים לאמן מודל שידע להבחין בין פריטים שונים, כאשר אין לנו מידע מה כל פריט מייצג. אחת הדרכים היעילות ביותר לבצע זאת הוא לאמן מודל שידע לייצר ייצוג עבור אותם פריטים באופן כזה שהייצוג (=האמבדינג) של אוגמנטציות של פריט (השומרות על התוכן הסמנטי) יהיו קרובות זו לזו, ואילו הייצוגים של אוגמנטציות של פריטים שונים יהיו רחוקים זה מזה. על ידי שימוש ברעיון הזה אימנו את המודל של CLIP – כאשר במקום אוגמנטציות של דוגמא לקחו זוגות של תמונה והתיאור המילולי שלה. מטרת האימון היא לייצר מרחב בו הייצוג של תמונה והתיאור המילולי שלה יהיו קרובים זה לזה כמה שיותר ואילו ייצוג של תמונה ותיאור של תמונה אחרת יהיו רחוקים אחד מהשני. בניית המרחב נעשתה על ידי אימון של 400 מיליון זוגות של תמונות ותיאורים, מה שהצליח לספק מרחב עם קשרים מאוד חזקים, וביצועים ברמה גבוהה במספר משימות קצה.
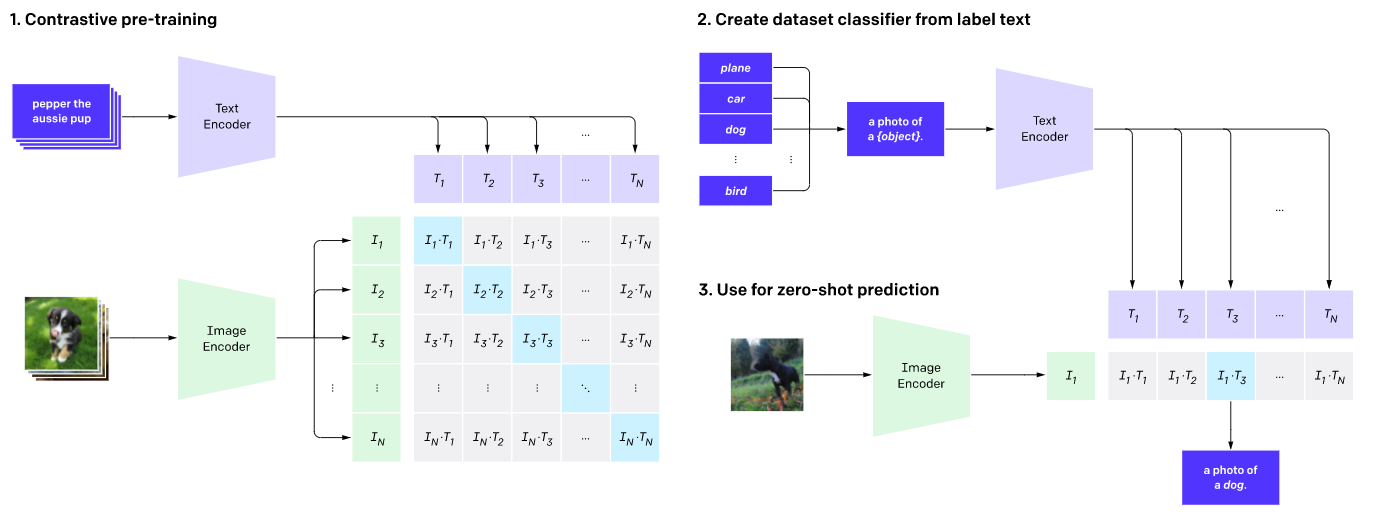
Source: https://openai.com/blog/clip/
כאמור, התוצאה המתקבלת של אימון זה הינו תיאור של תמונה וטקסט באותו מרחב, וניתן למנף אותו לבניית ייצוגים סמנטיים עוצמתיים של טקסט ותמונה. אם למשל נרצה לסווג אובייקטים בתמונה – אז המודל יתאר לנו את המתרחש בתמונה (התוכן הסמנטי), ומהתיאור נגזור את סוג האובייקט. באופן בו המודל אומן, הוא יוכל גם לתאר דברים שהוא לעולם לא ראה – המודל יוכל לפרש אותה באמצעות התיאור הכי סביר ביחס למרחב שמייצג אותה, וכיוון שבאותו מרחב יש ייצוג גם לטקסט, ניתן להגיע מאחד לשני.
כעת נחזור להתחלה – אם אימנו מודל להבחין בין כלבים וחתולים, לעולם הוא לא יידע מה זה רקון. אבל אם נאמן מודל שידע להתאים בין תמונה לתיאורה המילולי, הוא יוכל לדעת לתאר גם דברים שהוא לעולם לא ראה. איך? כי יש לו ייצוג שיודע לקשר בין תמונות לטקסט בצורה יעילה וטובה.
Source: https://openai.com/blog/clip/
מעניין לציין לעבודת המשך של חוקרים מתל אביב, שהתבססו על הרעיון של CLIP והשתמשו בו עבור משימת Image Captioning (בשונה מהעבודה המקורית שהראתה תוצאות על משימת קלאספיקציה). המחברים מציינים שתי בעיות באלגוריתמים הקיימים עבור משימה זו:
- בדרך כלל בשביל לאמן מודל כזה יש צורך בשני סוגים של דאטה מתויג – אחד שמכיל מידע על מיקום של אובייקטים ואחד שמכיל מידע (שאינו רק סיווג לקלאס) שמתאר אותם ואת שאר המתרחש. במילים אחרות – בשביל לאמן מודל של Image Captioning יש לערב אימון מודל שיודע לזהות את מיקום אובייקטים ולסווג אותם, ובנוסף צריך מודל שידע לקחת את המידע הזה ולספק עבורו תיאור מילולי מתאים.
- בגלל השילוב בין משימת הזיהוי למשימת התיאור המילולי, זמן האימון ארוך יחסית, ואף דורש הרבה דאטה. בנוסף, המורכבות של המודל יכולה לגרום לו להיות גדול, וממילא גם איטי ב-Inference.
המודל המוצע במאמר, שמבוסס כאמור על CLIP, מתגבר על שתי הבעיות האלו בצורה פשוטה ואלגנטית – האימון הוא רק על זוגות של תמונה והתיאור שלה, בלי צורך בעוד משימת Supervision נוספת. בנוסף, לא צריך כמות מאוד גדולה של דאטה עבור האימון, והזמן שלו מתקצר משמעותית. הפשטות היחסית של המודל מאפשרת לו להיות פחות כבד וממילא מהיר גם ב-Inference.
במאמר מציגים שני וריאנטים של אימון – אחד מבוסס fine-tuning למודל שפה אחר, והשני לוקח מודל שפה וממפה אותו ללא צורך ב-fine tuning. שני הוריאנטים מציגים ביצועים של State Of The Art מבחינת הצלחה במשימה, תוך קיצור זמן האימון (וה-Inference), בעזרת פחות דאטה (הן מבחינת הכמות והן מבחינת הסוג שלו).
Source: https://github.com/rmokady/CLIP_prefix_caption
חלק ג' – יצירת תמונה על פי טקסט
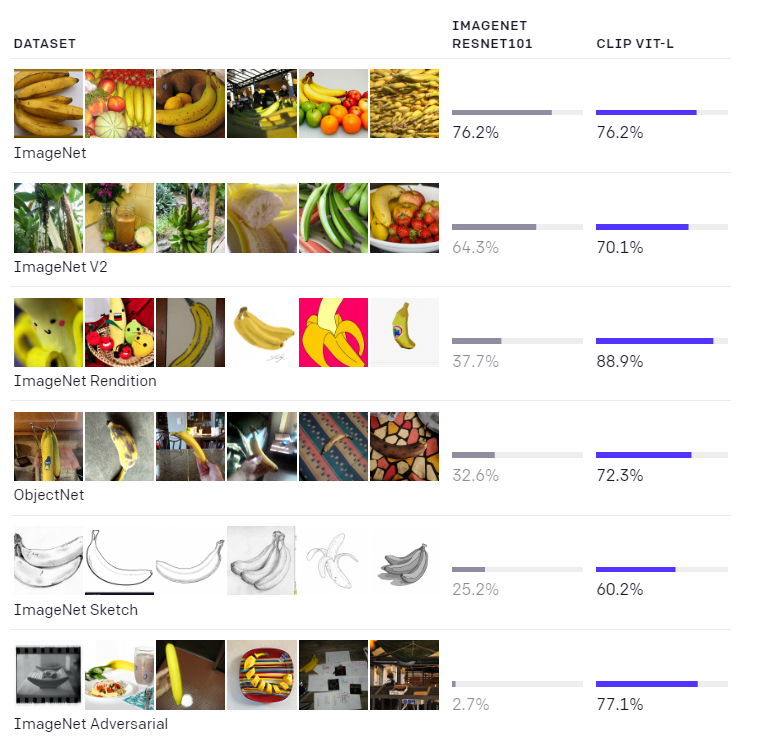
בפרק הקודם ראינו כיצד ניתן לשכן תמונות וטקסט באותו מרחב, כלומר, לתת לתמונה ולתיאור שלה ייצוג מתמטי קרוב במרחב רב-ממדי כלשהו. בניית המרחב נעשתה באמצעות הלמידה הניגודית על 400 מיליון זוגות של תמונות ותיאורים, מה שהצליח לספק מרחב עם קשרים מאוד חזקים, והצלחה ניכרת במגוון משימות קצה.
אחת ממשימות ההמשך המעניינות והיפות היא בנייה של GAN (גאן) שמנצל את המיפויים (בין דאטה ויזואלי/טקסטואלי למרחב הייצוג) ליצירת דאטה סינטטי. אם יש לנו מרחב בו תמונות והתיאורים שלהם ממוקמים יחד, אז נוכל להמיר בין טקסט לתמונה. בפרט, נוכל לאמן מודל שידע לקחת טקסט ולהמיר אותו לתמונה באמצעות שימוש באותו מרחב משותף.
אחרי שמבינים כיצד מקשרים בין טקסט לתמונות, בניית מודל גנרטיבי, המסוגל ליצור דוגמאות חדשות של דאטה, הוא עניין די מתבקש. לפני כמה חודשים OpenAI פרסמו עבודה בשם DALL-E שמטרתה היא לבנות גאן באמצעות השילוב של טקסט ותמונה. אמנם שם השתמשו בעוד כלים, אך אפשר לשאוב משם את הרעיון הזה של יצירת תמונה מטקסט על ידי מציאת ההתאמה ביניהן באותו מרחב משותף.
עבור כל תיאור מילולי שנכנס כקלט למודל, המודל מספק מגוון תמונות שיכולות להתאים לאותו תיאור. מבחינת זמן ריצה – תוך פחות משניה המודל מספק 512 תמונות, מתוכן נבחרות הכי מוצלחות (תמונה "מוצלחת" נמדדת על ידי הקרבה בין התיאור המילולי לתמונה במרחב המשותף המייצג תמונות וטקסט). לאחרונה יצאה עבודת המשך – DALL-E2 – ואני מניח שרבים כבר שמעו עליה בזכות התוצאות המדהימות שלה והבאזז שהיא יצרה.
Source: https://youtu.be/rdGVbPI42sA
חלק ד' – איך מודל יכול ליצור תמונות של instances שהוא מעולם לא ראה?
נמשיך עם יישום מעניין נוסף, המשלב בין הרעיונות המתוארים בפרקים הקודמים. הוא ייחודי בכך שבלי הייצוג המשותף – הוא על גבול הבלתי אפשרי. כאמור, האימון של המודל מתבצע על זוגות של תמונה וטקסט המתאר אותה, מתוך מטרה לייצג כל צמד של תמונה-טקסט במרחב כלשהו. הרציונל הוא לנסות לגרום לכך שגם הייצוג של התמונה וגם הייצוג של קטע הטקסט ימופו לנקודות קרובות באותו מרחב. כבר ראינו שאחת ההצלחות של מודל כזה היא בתחום של "zero shot" – סיווג אובייקטים שלא נראו בזמן האימון. בנוסף לכך ראינו שמודל כזה מצליח לשמש כמו גאן ולייצר תמונות מדהימות מתיאור מילולי.
כעת נלך צעד קדימה ונחבר בין שתי ההצלחות האלה – נבנה מודל שיודע ליצור תמונות של דברים שהוא לא ראה מעולם, על בסיס טקסט בלבד. יותר בפירוט: נניח ובשלב ראשון אימנו מודל על המון זוגות של תמונה-טקסט. כעת נוכל להוסיף עוד מידע טקסטואלי ללא תמונות, כלומר נלמד את המודל קשרים נוספים שיש בתוך טקסטים ואף נראה לו מילים חדשות. כעת נרצה שהוא ייצר לנו תמונות על בסיס משפטים המכילים תיאורים של תמונות שהמודל לא ראה בזמן האימון.
נדגים את שלושת השלבים באמצעות דוגמה קונקרטית:
ראשית, מכניסים למודל הרבה תמונות של בעלי חיים בכל מיני סיטואציות יחד עם משפטים המתארים את אותן סיטואציות. לאחר מכן נכניס לו משפטים על חיות נדירות שלא יוצגו בתמונות, כאשר משפטים אלו אינם מקושרים לתמונות. לבסוף נכניס למודל משפט המכיל את אותן חיות נדירות ונבקש ממנו לצייר אותן.
למעשה המודל נדרש לספק לנו תיאור ויזואלי של טקסט שהוא מקבל, כאשר הוא מעולם לא ראה תמונות של אותם אובייקטים המתוארים בטקסט. איך מודל יכול להצליח בכזו משימה? באמצעות הייצוג המשותף של טקסט ותמונות באותו מרחב! המודל לומד לשכן טקסט ותמונות באותו מרחב, ואז אם הוא מקבל טקסט, הוא יכול להסתכל על אותו מרחב ולתרגם לתמונה את אותה נקודה המתארת את הטקסט.
מדהים, לא?
עבודה שעושה משהו שמאוד קשור לרעיון המתואר: StyleGanNada (פורסמה על ידי חוקרים מתל אביב). שווה להסתכל בעמוד הפרוייקט, ואפילו יש דמו שניתן לשחק בו!
Source: https://stylegan-nada.github.io/
חלק ה' – סיכום, ומה הלאה?
בסקירה זו ראינו כיצד ניתן לייצג תמונות וטקסט באותו מרחב, ובעזרת הייצוג המשותף הזה לבנות מודלים המשלבים בין הדומיינים – אם זה בהבנה יותר טובה של סיטואציה, או ביצירה של תמונות על פי התיאור המילולי בלבד. כאמור, השילוב יכול לעבוד בשני הכיוונים – לייצר תמונות באמצעות טקסט, או ליצור טקסט המתאר תמונה (למשל Image captioning) ואפילו ראינו כיצד מודל יכול לצייר תמונות של דברים שהוא מעולם לא ראה.
השלב הבא יכלול כנראה הרבה עבודות שירחיבו את הגשר הזה למגוון אפליקציות מעניינות וחשובות. הנה למשל שתי דוגמאות של עבודות המשך שניתן לעשות:
- יצירה של וידאו באמצעות טקסט. זה בעצם לקחת את הרעיון של יצירת תמונות פוטוריאלסיטיות, ולהרחיב אותו ליצירה של וידאו. הרחבה זו היא המשך לוגי של אותו כיוון מחשבה, אך יחד עם זאת היא בוודאי קשה לביצוע בכמה סדרי גודל מאשר יצירה של תמונות בלבד.
- מענה על שאלות הקשורות לסצנה המופיעה בתמונה. נניח ויש תמונה ובה בעל חיים משחק בכדור, אז ראינו שמודל יכול לתאר את התמונה. ניתן להרחיב את היכולת הזו גם לאפשרות של מענה על שאלות, כמו למשל איפה נמצא בעל החיים, במה הוא משחק, כמה אובייקטים יש בתמונה וכו'. כמובן שאתגר זה של מענה על שאלות הקשורות להבנת התמונה הוא לא חדש לגמרי ויש מחקרים שמנסים לעשות זאת, אך פה ניתן להיעזר בייצוג הדאטה במרחב המשותף המתאר את הטקסט והתמונות יחד, מה שאולי יכול להקל על כזו משימה.
אז עד לכאן הסקירה על מגמה חשובה במחקר בשנה האחרונה של שילוב בין טקסט ותמונות, מקווה שעקבתם עד לכאן ושהיה מהנה 😊
הכתבה נכתבה על ידי אברהם רביב, בשיתוף עם מיכאל ארליכסון.
אברהם סטודנט לתואר שלישי בתחום של למידת מכונה באוניברסיטת בר-אילן ועובד בחברת סמסונג. מתעניין בלמידה עמוקה ומגוון יישומים כולל ראייה ממוחשבת ועיבוד שפה טבעית. מרצה ומנגיש בעברית חומרים בתחום הבינה המלאכותית, ומחבר ספר על למידת מכונה ולמידה עמוקה בעברית.
מיכאל עובד בחברת הסייבר Salt Security בתור Principal Data Scientist. מיכאל חוקר ופועל בתחום הלמידה העמוקה, ולצד זאת מרצה ומנגיש את החומרים המדעיים לקהל הרחב.


