לקט שבועי מתמלא של סקירות קצרות של #shorthebrewpapereviews

21.07.23: TokenFlow: Consistent Diffusion Features for Consistent Video Editing
https://huggingface.co/papers/2307.10373
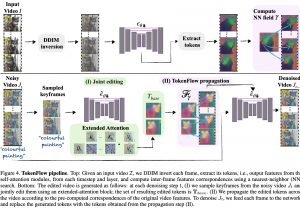
היום סוקרים מאמר כחול-לבן ב #shorthebrewpapereviews חוסר רציפות בין הפריימים: מה הבעיה הגדולה ביותר בעריכה של וידאו עם באמצעות מודלי דיפוזיה גנרטיביים? מודלי דיפוזיה מסתדרים יפה עם עריכת תמונות לפי תאור טקסטואלי אבל עם הוידאו הסיפור יותר מסובך כי נדרשת רציפות בין פריימים. הדרך הנאיבית לבצע עריכת וידאו בהתאם לתיאור טקסטואלי היא לערוך כל פריים (תמונה). אבל איך נשמור על קוהרנטיות בין הפריימים הערוכים? המחברים לוקחים פיצרים של הפריימים הסמוכים ומהשתמשים בהם כדי להחליק את וידאו ערוך בעזרת אינטרפולציה של הפיצ'רים שלו עם הפריימים הקרובים לו. אבל אלו פיצ'רים של הפריימים כדאי לקחת? קודם כל המחברים לוקחים את את השאילתות, מפתחות וערכים (queries, keys, values) ממנגנוני ה-attention מכמה פריימים סמוכים של הוידאו המקורי. לאחר מכן עבור פריים i מפעילים מנגונן-attention על השאילתה שלו ועל המפתחות והערכים של הפריימים האחרים. ככה למעשה מחושב ״צוג הרציפות״ של הוידאו המקורי (המורכב מייצוג של כל פריים ביחס לפריימים האחרים). לכל פריים מחפשים את הפריים שבא לפניו ואחד שבא אחריו עם ה-attention (בין q, k, v שהסברנו קודם) הקרוב ביותר לפי מרחק הקוסינוס מבחינת ייצוג הרציפות. ואז עבור כל פריים שאנחנו עורכים אנו משפרים את הרציפות שלו עם הפריימים אחרים תוך שמירה על אותו ״ייצוג רציפות״ כמו בוידאו המקורי על ידי אינטרפולציה שלו באמצעות שני ייצוגי הרציפות של הפריימים שמצאנו.

22.07.23: Meta-Transformer: A Unified Framework for Multimodal Learning
https://huggingface.co/papers/2307.10802
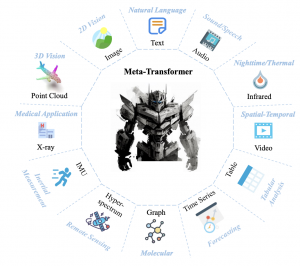
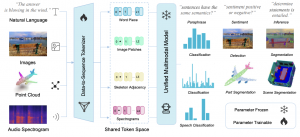
זוכרים את ImageBind של מטא עם המודל שלהם מקבל דאטה מ-6 סוגים שונים. זה היה מרשים נכון? אז! עכשיו ב-shorthebrewpapereviews# קבלו את Meta-Transformer שיודע לעבוד עם לא פחות מ 12 סוגים שונים של דאטה כולל דאטה טבלאי, סדרות עתיות, קרינה אינפרארד,גרפים, ואפילו דאטה מצילומי רנטגן. בגדול הם הצליחו לבצע טוקניזציה ״יוניפורמית״ לכל סוגי הדאטה האלו ואחריה בא המקודד שמשכן (embed) אותם לאותו המרחב. נראה לכם דמיוני? גם לי האמת אז בואו נצלול(טיפה) לפרטים של טוקניזציה של כמה סוגים של דאטה: לתמונות ולטקסט זה די ברור ומובן אבל איך נעשה טוקניזציה לענן נקודות למשל? כאן משמתמשים בשיטת Farthest Point Sampling (FPS) שדוגם תת קבוצה של נקודות הענן באופן אחיד ולאחר מכן מקלסטרים את הנקודות סביב נקודות אלו לפי k-nearest neighbors. כל קלסטר יהווה טוקן שיוכנס למקודד. בנסוף לטוקנים מכניסים לאנקודר את הטוקן המיוחד המכיל את סוג הדאטה. מכיוון שמשתמשים בטנרספורמרים מכניסים בנוסף גם את קידוד תלוי המיקום (positional encoding). בקיצור הרחבה נחמדה של ImageBind.
23.07.23
https://cogtoolslab.github.io/pdf/mukherjee_cogsci_2023.pdf
האם מודלים של ויז'ן ״מבינים״ את עולם הויזואלי בדומה לנו, בני האדם? האם הם ״מהבינים״ קונספטים אבסטרקטיים כמו סקיצה של תמונה? היום ו ב-shorthebrewpapereviews# מאמר מגניב, חמוד ולא רגיל הבודק את היכולת של מודלי ויז'ן חזקים להבחין אובייקטים (חיות) על סמך הסקיצות שלהם בלבד. הם בדקו את זה על סקיצות מפורטות יותר (שמכילים יותר פרטים על האובייקט) וגם כאלו מאוד סכמתיים שמכילים כמה קווים שניתן לצייר אותם ב-8 שניות (לא אדם כמוני שלא יודע לצייר אלא מישהו עם קצת יכולות). אנחנו, בני האדם, ברוב המקרים לא מתקשים לזהות אריה גם לפי סקיצה מאוד בסיסית שלו. לעומת הזאת המודלים החזקים שלנו כמו CLIP או VIT-B די מתבלבלים עם הסקיצות ומתקשים לזהות אובייקטים בסקיצות שלהם. כמובן אתם שהמודלים האלו לא אומנו על הסקיצות ולא צפוים לעבוד טוב עליהם, עדיין ההבנה הזו היא נחמדה. המחברים גם בדקו האם הסקיצות שנוצרות באמצעות מודל גנרטיבי(CLIPasso) הם ״מובנים״ על ידי בני האדם כמו הסקיצות הטבעיות. מתברר שהסקיצות המצוירות על ידי מובנות לבני אדם באותה רמה כמו הסקיצות הטבעיות המפורטות (של 30 שניות). לדעתי זו תגלית די מעניינת.

24.07.23

נכון שלא תמיד מודלי הדיפוזיה שלכם מציירים לכם תמונות ממש לא יפות? לא מבחינת התכון אלא מבחינת איכות התמונה! המאמר שנסקור קצרות ב- #shorthebrewpapereviews היום מדבר על הסיבות האפשריות. כמו שאתם בטח יודעים מודלים דיפוזיה מתחילים מתמונה שהיא רעש גאוסי טהור ואז מנקים ממנה את הרעש בהדרגה. שערוך הרעש המנוקה מתבצע באמצעות רשת נוירונים מאומנת. ניתן לתאר את תהליך הניקוי מרעש ההדרגתי כפתרון נומרי של ידי משוואה דיפרנציאילית (שהיא בזמן רציף). כדי לאפשר יצירת דאטה מהירה (אתם לא רוצים לחכות דקה כדאי לראות את התמונה שהזמנתם, נכון). בשביל זה פותרים את המשוואה הדיפרנציאלית הזו בפחות איטרציות (צעדים) תוך כדי מזעור הפגיעה באיכות התמונה. לצערנו זה לא תמיד עובד ולפעמים יוצאים לנו כל מיני ארטפקטים לא יפים בתמונות שלנו. המחברים חקרו את התופעה הזו והגיע למסקנה שאחת סיבות לכך יכולה להיות גלישה לאיזור ״אי היציבות״ של הפתרון הנומרי של המשוואה הדיפרנציאלית שאנו פותרים. כלומר הפתרון הנומרי מתבדר ומגיע לערכים המקסימליים של הצבעים (אדום, כחול ו/או ירוק). זה מה שמביא לארטפקטים המעצבנים האלו. ההמאמר מציע שיטה לפתרון נומרי של משוואה דיפרנציאלית זו שהיא יותר יציבה ואז התמונות שלנו יוצאות נקיות. דרך אגב מבחינה קונצפטואלית, הפתרון הנומרי המוצא דומה מאוד למומנטום של נסטרוב ששיפר לנו מאוד את SGD וגם גרם להתכנסות מהירה יותר של אימון רשתות נוירונים.

25.07.23
https://arxiv.org/abs/2307.12560.pdf
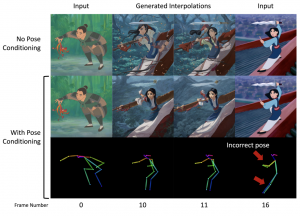
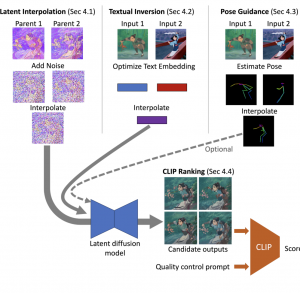
האם אתם יודעים שניתן להפוך תמונה אחת לתמונה אחרת הצורה רציפה וחלקה באמצעות מודלי דיפוזיה. כלומר לוקחים תמונה של רוק ועל ידי שינויים קטנים והדרגתיים הופכים אותו לתמונה של שרק. היום ב- #shorthebrewpapereviews מדברים על איך עושים זאת באמצעות מודלי דיפוזיה. קודם כל לוקחים את שתי התמונות ומעבירים אותן למרחב הלטנטי. הגישה הנאיבית (שלא מצריכה מודלי דיפוזיה) היתה לבצע אינטרפולציה לינארית הדרגתית מהייצוג הלטנטי של התמונה הראשונה בכיוון של הייצוג הלטנטי של התמונה השנייה. ואז מעבירים את הייצוג הלטנטי המשוערך לתמונת ביניים עם הדקודר. הגישה הנאיבית הזו לא עובדת כל כך טוב. במקום זאת מוספים רעש לייצוגים, משתמשים באותה אינטרפולציה עבורם ואז משתמשים במודלי דיפוזיה כדי לנקות את הרעש (בסוף מעבירים את התוצאה דרך הדקודר כדי ליצור תמונה). כלומר כדי ליצור תמונה N/2 מתוך N תמונות ב״שרשרת השינוי״ ממצעים את הייצוגים הלטנטיים של שתי תמונות המקור, כדי ליצור תמונה בשלב 3N/4 ממצעים ייצוגים מורעשים בשלב N ו- N/2. כמה רעש מוסיפים? ככל שהתמונות בשרשרת השינוי רחוקים יותר מוסיפים יותר רעש כי זה מאפשר לבחון ״יותר אפשרויות לאינטרפולציה״ במרחב הלטנטי. האם זה מספיק? לא תמיד. כאשר יש לנו תיאור טקסטואלי לתמונות האלו ניתן למנף אותו לשיפור איכות ״שרשרת השינוי״. כדי להשיג זאת המאמר גם מכייל את האנקודר עבור כל תמונה במטרה להתאים אותו יותר לתמונה (תוך מזעור של שגיאת השחזור הרעש של מודל דיפוזיה מאומן SD). המאמר גם משתמש ב-pose של התמונות כדי לשפר את ביצועי המודל שלהם. כדי לקבל pose של תמונה הביניים עושים אינטרפולציה של ה-poses של התמונות המקוריות (מוסיפים אותו כהתניה נוספת למודל דיפוזיה המנקה את הרעש).
26.07.23
https://huggingface.co/papers/2307.13269

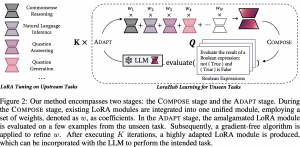
האם יצא לכם לכייל מודל שפה לכמה משימות בו זמנית מכמה דוגמאות נתונות לכל משימה? כלומר אתם כן רוצים לשנות את משקלי המודל אבל לא רוצים להשתמש ב-gradient descent בשביל לעשות זאת כי אין ברשותכם מעבד חזק. הויום ב-#shorthebrewpapereviews מאמר שמציע שיטה לעשות את זה. המחברים משתמשים בכוכב העולה בעולם כיול #llms הנקרא LoRa. זו שיטה לכיול #llm שבמקום לאמן את המשקלים עצמם מואמנת למצוא את התוספות האופטימליות למשקלים (=מטריצות של דלטאות). בנוסף על כל תוספת מניחים שהיא בעלך רנק נמוך וניתן לתאר אותה כמכפלה של שתימטריצות A ו- B בעלות רנק נמוך גם כן שמאפשר להקטין משמעותית את מספר המשקלים המכוילים ובכך להפוך אותו ליותר יעיל וקצר. אז בואו נניח של שיש לנו מטריצות A ו-B לכל משימה שאנו רוצים לכייל את מודל השפה והמטרה שלנו למצוא של מטריצת הדלטאות האופטימלית לכל המשימות יחד W. אז המחברים למעשה מתארים את W בתור מכפלה של הסכומים הממושקלים של מטריצות A לכל המשימות עם אותו סכום ממושקל של מטריצות B (עם אותן המשקלות). ואת המשקלות האלו אנו מאפטמים כדי לבנות את W שמתאימה לכל המשימות יחד עם כל הדוגמאות עבור המשימות האלו. מכיוון שמספר הפרמטרים המאופטמים הינו די קטן, המאמר משתמש בשיטה הנקראת Covariance Matrix Adaptive Evolution Strategies (CMA-ES) שהיא דורשת חישוב הגרדיאנט. זה שיטה שמחפשת במרחב הפרמטרים על ידי חישוב של פונקציית המחיר עבור סט של פרמטרים ואז מנסה לבחור את סט הפרמטרים הבא בכיוון שמקטין את פונקציית המחיר. בכך הם משתמשים בסוג של קורלציה משוערכת של כל פרמטר עם פונקציית המחיר (איך הוא משפיע על התוצאה). נזכיר שכאן פונקציית המחיר מודדת את הביצועים של הרשת עם מטריצת הדלטאות W על הדוגמאות מכל המשימות.
27.07.23
https://huggingface.co/papers/2307.13720

רציתם פעם לצייר תמונה מפאצ'ים עם תוכן שאתם מגדירים? למשל שבפינה השמאלית העליונה יהיה לנו חתול שר, בפינה הימנית העליונה יהיה לנו אביר בתלבושת האבירים ולמטה יהיה לנו תמונה של נסיכה. זה כבר לא חלום – היום ב- #shorthebrewpapereviews סוקרים מאמר שעושה בדיוק את זה. אתם נותנים למודל שלהם את התמונות (פאצ'ים) שאתם רוצים לראות בתמונה היעד שלכם או תיאור של התמונות האלה ובנוסף מגדירים את המיקומים של הפאצ'ים אלה בתמונה היעד והמודל שהם אימנו מצייר לכם תמונה שהפאצ'ים במיקומים שהגדרתם. המחברים עושים זאת בשני שלבים. בשלב הראשון משתמשים במודל דיפוזיה מאומן כדי ליצור כל פאץ' של בנפרד מהתיאור שלו או במקרה של תמונות נתונות לכל פאץ' מוסיפים רעש לכל אחד מהם מנקים אותו עם מודל דיפוזיה. הקאטץ' כאן שלא מורידים את הרעש עד סוף אלא עד איטרציה k מסך כל n איטרציות של מודל הדיפוזיה. חשוב לציין שכל פאץ' מנוקה מהרעש באופן עמצאי. בשלב השני ממשיכים לנקות את הפאצ'ים מהמרעש אבל הפעם מכניסים למודל דיפוזיה ״המנקה״ את הייצוג של כל התמונה ובנוסף מיקום של כל פאץ'. כלומר בשלב הראשון אנו יוצרים את התוכן של כל פאץ' ובשלב השני אנו ״מחליקים״ את תמונת היעד כך שהגבולות בין הפאצ'ים השונים יהיה חלקים ובלתי מזוהים לעין. ככל שמספר האיטרציות בשלב הראשון גבוה יותר, אז יותר מקפידים על התוכן של כל פאץ' וכאשר מקטינים את k משקיעים יותר ברציפות בין-פאצ'ית של תמונת היעד.



