לקט שבועי מתמלא של סקירות קצרות של #shorthebrewpapereviews, שבוע 28.07-03.08

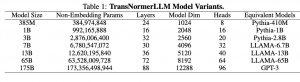
28.07.23: Scaling TransNormer to 175 Billion Parameters
https://huggingface.co/papers/2307.14995
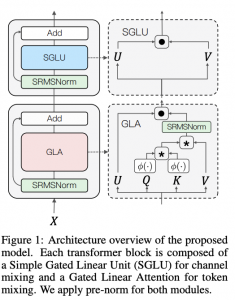
29.07.23: RLCD: REINFORCEMENT LEARNING FROM CONTRAST DISTILLATION FOR LANGUAGE MODEL ALIGNMENT
https://huggingface.co/papers/2307.12950

30.07.23: DoG is SGD’s Best Friend: A Parameter-Free Dynamic Step Size Schedule
https://arxiv.org/abs/2302.12022.pdf
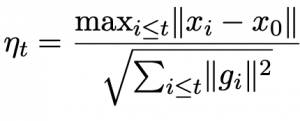
נכון שכל פעם שאתם מאמנים רשתות אחד הפרמטרים שאתם צריכים להחליט עליו הוא קצב למידה (learning rate)? גם כאשר אתם משתמשים ב-adam אתם צריכים לבחור אותו. נכון שיש ערכים דפולטיים ש״אמורים לעבוד טוב עבור כל בעיה״ אבל עדיין בחירה לא טובה של קצב למידה עלולה להוביל לאימון ליעיל. אז היום ב-shorthebrewpapereviews סוקרים מאמר המציע שיטה פשוטה שבה לא צריך לבחור קצב למידה ל-SGD והוא מחושב לפי נוסחה סגורה. קצב למידה(learning rate) תלוי במרחק המקסימלי בין הנקודה שאנו כרגע נמצאים בה מנקודת ההתחלה (= וקטור משקלים התחלתי) וגם בסכום של נורמות של גרדיאנטים עבור T הנקודות הקודמות. כלומר ככל שאנו ״הצלחנו להתרחק״ יותר מנקודת ההתחלה אנו מעלים את קצב הלמידה ובנוסף הוא ״מרוסן״ באמצעות סכום הגרדיאנטים שנצברו עד כה. הבחירה של הנוסחה הזו נובעת מהתוצאה התאורטית האומרת אם עבור SGD (Stochastic Gradient Descent) עם קצב למידה ומספר איטרציות T קבועים, שקובעת שקצב למידה מקיים את הנוסחה המוצעת מוכפלת בקבוע c אז ניתן לחסום את אי האופטימליות שלו יחסית ל-SGD האופטימלי (עם הגורם התלוי בקבוע c). אבל כמובן שאנו לא רוצים להריץ T איטרציה בשביל לקבוע את קצב הלמידה. אז בוחרים אותו עם מקדם c=1 בכל איטרציה (לניתוח יותר מעמיק ועם כל ההוכחות ניתן למצוא במאמר עצמו).
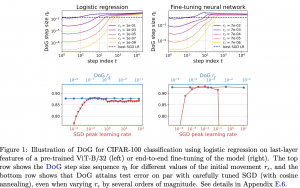
31.07.23: Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
https://huggingface.co/papers/2307.15337
אתם בטח יודעים שמודלי שפה יוצרים טקסט טוקן לאחר טוקן. כלומר כדי ליצור את המילה השלישית אנו צריכים לגנרט את המילה הראשונה ואת השנייה. גנרוט סדרתי שכזה כמובן מאט את גנרוט הטקסט על ידי מודלי שפה ואנו נאלצים לחכות יותר זמן בשביל לקבל את התשובה. נשאלת השאלה האם ניתן להאיץ את הגנרוט? היום ב- #shorthebrewpapereviews אנו סוקרים מאמר שמצליח לזרז את גנרוט הטקסט על יד מודלי שפה באמצעות טריק מאוד פשוט ואלגנטי. במקום ליצור את כל התשובה יחד מודל שפה קודם כל יוצר את הסקיצה של התשובה (נגיד בתור רשימת נושאים) ואז מעביר את השרביט לכמה מודלי שפה שכל אחד מהם מגנרט תשובה עבור כל אחד מהנושאים שנוצרו. למשל אם אתם שואלים מודל שפה על מאכלים סיניים אז בשלב הראשון הוא יוצר רשימת של שמות המאכלים בלבד ובשלב השני כמה (רפליקות) מודלי שפה מרחיבות על כל סוג של מאכל. כמו שאתם כבר מבינים ככה ניתן למקבל את גנרוט הטקסט כי יצירת סקיצה קצרה אמורה לקחת מעט מאוד זמן. כמובן יש כמה טריקים איך לגרום למודל שפה ליצור סקיצת תשובה קצרה (אחד מהם הוא פשוט להגיד לו ליצור רשימה של תשובות קצרות). עם הטריק הפשוט זה המחברים הצליחו לזרז גנרוט עד פי 2.39!

01.08.23: UnIVAL: Unified Model for Image, Video, Audio and Language Tasks
https://huggingface.co/papers/2307.16184
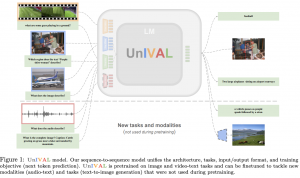
מכירים את המודלים המולטימודליים כמו ImageBind של מטה והמודל הטרי Med-PaLM שיכולים לעבוד עם סוגים שונים של דאטה? מודלים אלו מכילים עשרות מיליארדים של פרמטרים והם גם מאומנים על דאטהסטים עצומים. האם ניתן לאמן מודל מולטימודלי יחסית קטן שלא דורש כמויות עצומות של דאטה לאימון? היום ב- #shorthebrewpapereviews סוקרים מאמר שמחבריו טוענים שהם הצליחו לאמן מודלי מולטימודלי קטן יחסי היודע לשפה טבעית, תמונות, וידאו ואודיו. איך הם עשו זאת? הם אימנו (pretraining) את המודל שלהם קודם כל על משימות פשוטות יותר (כמו מידול שפה שזה יותר פשוט ממשימות מולטימודליות) ואז המשיכו לאמן אותו על משימות המערבות טקסט ותמונות. לאחר מכן הם הלכו ונתנו למודל משימות קשות יותר דרך הוספה של מודליטי נוסף לדאטה מהשלב הקודם. הם קראו לשיטה הזו למידה cirruculum מולטימודלי. המחברים טוענים שככה המודל לומד לייצג כל מודליטי במרחב השיכון המשותף. כלומר מתחילים מאמנים כמה אפוקים על משימה פשוטה וכל כמה אפוקים מוספים סוג דאטה נוסף ו״מסבכים״ את המשימה. דרך אגב שמודל כזה מצריך טוקניזציה שתתרגם סוגי דאטה שונים לאותו מרחב. התוצאות של המודל מציג תוצאות לא רעות ביחס למודלים גדולים הרבה יותר ממנו.
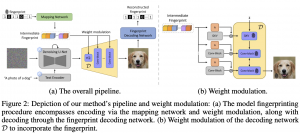
02.08.23: WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models
https://huggingface.co/papers/2306.04744
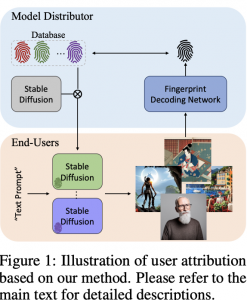
נניח שהצלחתם להנדס פרומפט מאוד מוצלח ל-Midjourney והוא צייר לכם תמונה מדהימה.אם אתם לא רוצים שאף אחד ישתמש בתמונה הזו בלי לתת לכם קרדיט. אבל איך אתם מוכיחים שאתם בעצם יצרתם את התמונה הזו? אתם צריכים להחביא בתמונה איזה סימן מים משלכם (watermark) כדי שתוכלו להוכיח את בעלותכם. היום ב-#shorthebrewpapereviews סוקרים מאמר המציע שיטה להוספה של סימן מים המאפשרת להגיד האם תמונה נתונה נוצרה על ידיכם. יש שתי דרישות מסימני מים על התמונות המגונרטות. הדרישה הראשונה שהתמונות שנוצרו עבור אותו פרומפט (ואותו seed) עם ובלי סימן מים צריכות להיות מאוד דומות. הדרישה השנייה היא שניתן לשחזר את סימן המים הזה מהתמונה בצורה יחסית מדויקת. המחברים מציעים להוסיף את סימן המים הזה למפענח(decoder) של מודל Stable Diffusion. איך זה נעשה? קודם כל מגרילים וקטור בינארי, מקודדים אותו עם רשת A מאומנת כדי ליצור מסכות לכל שכבה. למעשה כל נוירון של הפלט של כל שכבה של הדקודר מוכפל בפלט של A (כל שכבה ממוסכת בנפרד). כדי לשחזר סימן מים מאמנים עוד רשת שהקלט F (שהיא ResNet50) שלה היא תמונה והפלט שלה היא סימן המים עליה. פונקציית לוס כאן מורכבת משני איברים: הראשון מיועד לאימון של רשת F (לוס בינארי על כל ביט של סימן המים) והשני דואג שהסופת של סימן המים לא ישנה את התמונה יותר מדי דרך מזעור של perceptual loss בין התמונה עם סימן מים וזו שבלעדיו.
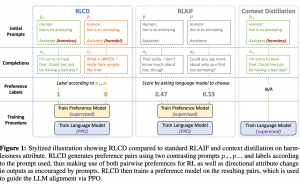
03.08.23: From Sparse to Soft Mixtures of Experts

ערבוב של מומחים (mixture of expers) – שמעתם על זה? כשיש לכם משימה מורכבת ביד אחת הגישות לפתור אותם היא לחלק אותה לכמה תת-משימות בעלות אופי שונה ואז מאמנים מודל לכל אחד מהמשימות אלו. בסוף משלבים את התוצאות של כל מודלים לבניית הפתרון לבעיה המורכבת שלנו. המאמר שנסקור היום ב-#shorthebrewpapereviews סוקרים מאמר המציע גישה חדשה, פשוטה ואלגנטית לביצוע MoE המאפשרת להקטין את כמות החישוב הנדרש לאימון המודל למודלים עצומים בגודל (בגדול טרנספורמרים). בעבר שיטות MoE k דלילות (sparse) חילקו פיסת דאטה (נגיד טקסט או תמונה) לכמה חלקים שונים ואז כל מודל מתאמן רק על חלק מפיסת הדאטה וככה היה נחסכת כמות נכבדת של חישובים. לגישה זו יש כמה חסרונות כמו התפלגות מאוד לא שוויונית של הדאטה בין המודלים המומחים, אימון לא יציב וקושי לעשות סקייל מספר המומחים. הגישה המוצעות מציעה פתרון מאוד אלגנטי לסוגיות אלה – במקום לחלק את פיסת הדאטה בין המודלים המומחים כל אחד מקבל קומביציה לינארית שונה (או כמה) של כל חלקי הדאטה. כך כל מודל רואה את כל פיסת הדאטה במלאו אבל עם זאת זה מאפשר להקטין משמעתית את מספר החישובים. אהבתי!
ֿ