לקט מתמלא של סקירות קצרות של #shorthebrewpapereviews, החל מ- 25.11.23

TOOLCHAIN* : EFFICIENT ACTION SPACE NAVIGATION IN LARGE LANGUAGE MODELS WITH A* SEARCH
https://huggingface.co/papers/2310.13227


Matryoshka Diffusion Models
https://huggingface.co/papers/2310.15111

סקירה של היום היא על שילוב של מילה ברוסית (מטריושקה או בבושקה בעברית) ומודלי דיפוזיה. משתמע מכך נדבר על הרבה מודלי דיפוזיה אחת בתוך השנייה כמו שמקובל במטריושקה. אז היום ב-#shorthebrewpapereviews סוקרים מאמר שלקח רעיון של ProGAN והטיל אותו על מודלי דיפוזיה.
ללצעירים בינינו ֿ ProGAN הוא גישה, מבוססת על GANs (שיטה גנרטיבית שולטת לפני מודלי הדיפוזיה) שמתחילה יצירת תמונה בעלת רזולוציה גבוהה מיצירת תמונה מרזולוציה נמוכה מאוד. לאחר מכן היא יוצרת ממנה תמונה ברזולוציה גבוהה יותר (נגיד פי 2) בכל שלב עד שמגיעים לתמונה ברזולוציה הנדרשת. אז איך בעצם מטילים את הרעיון הנחמד הזה על מודלי דיפוזיה? כמו שאתם זוכרים מודלי דיפוזיה יוצרים תמונות מרעש טהור כאשר בכל שלב (איטרציה) מורידים קצת רעש מהתמונה עד שמגיעים לתמונה הנקייה. אז בשיטה המוצעת מציעים לבצע את התהליך הזה על תמונה מרזולוציות שונות בו זמנית. כלומר כאשר אנו מורידים רעש באיטרציה t (כדי לקבל תמונה מאיטרציה t-1) ברזולוציה מסוימת R אנחנו משתמשים לא רק בתמונה מאיטרציה t של התמונה מרזולוציה R אלא בתמונות מכל הרזולוציות האפשריות.
קודם כל זה משפר את איכות השערוך כי למודל יש מידע נוסף לגבי התמונה. בנוסף המאמר מציע לאמן את מודל בצורה פרוגרסיבית (בקטע טוב כאן). זאת אומרת מתחילים לאמן מודל דיפוזיה החל מרזולוציה הנמוכה ואז ממשיכים לרוזלוציות גבוהות יותר תוך כדי ניצול מודלי דיפוזיה מאומנים מרזולוציות נמוכות (לא לגמרי ברור האם המודלים מרזולוציות נמוכות מאומנות תוך כדי אימון של הרזולוציות גבוהות). התוצאות די מרשימות אבל לא ראיתי התייחסות לזמן יצירה גבוה יותר (או יותר משאבי חישוב) ממודל דיפוזיה סטנדרטי. הסיבה לכך נעוצה בעובדה כי בשביל לגנרט תמונה מרזולוציה גבוהה צריך כל פעם ליצור תמונות מרזולוציה נמוכה בכל איטרציה. אבל עדיין רעיון נחמד מאוד.

Localizing and Editing Knowledge in Text-to-Image Generative Models

מודלי דיפוזיה ממשיכים לשלוט ב AI גנרטיבי כבר זמן מה ואחד נושאי המחקר החמים ביותר בנושא הזה הוא עריכת תמונות המגונרטות עם מודלים אלו. לאחרונה יצאו לא מעט שיטות שמצליחות למשל להוריד אובייקט מתמונה, להחליף אותו לאובייקט אחר או לשנות את סגנון התמונה. המאמר שנסקור היום מציע שיטה לעריכת תמונות המגונרטות עם מודלי דיפוזיה בצורה מאוד אלגנטית המתבסס על ההבנה של מה שקורה בתוך מודל הדיפוזיה (שזה אנקודר של טקסט ומודל המסיר רעש מתמונה UNet בכל איטרציה).כלומר בשלב הראשון המאמר מנסה להבין איזה חלק(שכבה) במודל להסרת הרעש אחראי על יצירה של כל אובייקט בתמונה, איזו שכבה אחראית על הסגנון, ואיזו מהשכבות אחראית על צבע. איך עושים זאת? קודם כל מוסיפים את הרעש לטוקן האחרון של האובייקט/סגנון/צבע בתיאור הטקסטואלי. למה אותו דווקא?
המאמר בדק ומצא (על ידי השימוש ב Clip-Score המודד את איכות התמונה המגונרטת והתאמתה לתיאור) שזה מה שמשפיע יישות שרוצים לערוך (למשל מעלים אובייקט). אז איך עושים עריכה? מכיוון שהשכבה הראשונה אחרי שכבת האמבדינג באנקודר היא קריטית אז מאמנים רק אותה (את חלקה). מכיוון שיש לנו טרנספורמרים כאן אז השכבה מוגדרת על ידי 4 מטריצות: W_q, W_k, W_v ו- W_out.
שלוש המטריצות הראשונות הן מטריצות ממנגנון ה-attention ומשאירים אותן כמו שהן ומאמנים רק את W_out (לצורך עריכה) תוך כדי שימוש בשיכונים (embeddings) של האובייקט(או סגנון) הישן והחדש c_k ו-c_v בהתאמה. פונקצייה שמאפטמים אותה כדי למצוא את W_out מרמזת על כך שהמטרה(לא לגמרי הפנמתי מה הרציונל כאן) היא למצוא W_out חדשה כך שפלט של השכבה הראשונה ״החדשה״ עבור c_k (הישן) תהיה כמה שיותר קרובה לפלט של השכבה המקורית עם c_v (החדש) עם רגולריזציה קטנה. והכי כיף שניתן לפתר בעיה זו בצורה סגורה ואין צורך באימון שזה מגניב. לבסוף הם עשו עוד דבר נחמד.
הם מצאו שיש שכבה מסויומת במודל להסרת הרעש שאם מעתיקים את האקטיבציות שלה עבור הקלט הטקסטואלי הלא מורעש האובייקט ״הנערך״ חוזר לתמונה המגונרטת. שימו לב שמכיוון של הארכיטקטורה של המודל מבוססת על ResNet זה התוצאה מההזנה של הקלט המורעש לא זהה לזו של לקלט הלא מורעש. אבל כן מקבלים תמונה דומה עם אותו האובייקט. וכמובן ששכבות שונות אחריות על שינוי צבע, סגנון וכדומה.

Teaching Language Models to Self-Improve through Interactive Demonstrations
https://huggingface.co/papers/2310.13522

ממודלי דיפוזיה שסקרנו אתמול עוברים לאייטם פופולרי אפילו אפילו מהם כלומר מודלי שפה ענקיים (LLMs). המאמר שנסקור היום מציע שיטה לאימון LLMs קטנים יחסית (מיליארדי פרמטרים בודדים) לפתרון בעיות מתמטיות מורכבות (נניח כאלו שמכילות הרבה פעולות).
המאמר מציין שמודלי קטנים יחסית מתקשים לפתור בעיות בעזרת reasoning אם מפעילים אותו (המודל) בצורה של few-shot, כלומר מספקים לו כמה דוגמאות עם פתרון מלא. בגדול המאמר מציע לאמן (מכייל) מודל שפה קטן L על הטעיות שלו. עבור בעיה נתונה מפעילים מודל L כדי ליצור שרשרת צעדי חשיבה לפתרון בעיה זו. לאחרי מכן מפעילים מודל יותר חזק (נגיד codex) לפתרון בעיה זו ומשווים את שרשרת החשיבה של שניהם. במקום הראשון שהם שונים מחליפים את המשוב של המודל החלש בזה של המודל החזק. לאחר מכן מפעילים מודל חזק שוב פעם כדי לתקן את שרשרת החשיבה של המודל החלש מהמקום הזה. לאחר מכן מחלקים את הדאטהסט הזה (יש בו פתרונות זהב ground-truth, פתרונות נכונים של המודל החלש, והפתרונות המתוקנים על ידי המודל החזק). אז מחלקים את הפתרונות האלו לפי התוצאה הסופית (נכונה או לא נכונה).
את הפתרונות הנכונים מחלקים לשלישיות של (תוצאה של שלב i, המשוב והתוצאה של השלב החדש). אלו שמסתיימים בפתרון האחרון מחלקים לזוגות (שלב i, משוב). בסוף מאמנים מודל קטן על הדאטסט הזה תוך משקול שונה לשלישיות והזוגות מהשלב הקודם. מטרת האימון היא חיזוי הטוקן הבא כמו שמקובל באימון מוקדם של מודלי שפה. ככה מצליחים לשפר את הביצועים של המודל הקטן במשימות מורכבות של reasoning.

In-Context Learning Creates Task Vectors
https://huggingface.co/papers/2310.15916

אחד היכולות המדהימות של מודלי שפה ענקיים היא יכולת למידת in-context או ICL בקצרה. ICL היא יכולת של LLM ללמוד מכמה דוגמאות בלי לשנות בכלל את המשקלים שלו. כלומר אנו מעבירים למודל שפה כמה דוגמאות בסגנון (מלון -> צהוב, מלפפון -> ירוק,..) ולאחר המכן אם תזינו למודל ״בננה -> …״, הוא יבין שמדובר בצבע ויענה צהוב.
אבל איך המנגנון הזה עובד? המאמר המסוקר טוען ומראה שמדובר כאן בתהליך דו שלבי: – הזנה של הדוגמאות (נסמן אותם ב S) המחשבים את הפרמטרים של פונקציה מסוימת (בהמשך נסביר איך היא בנויה) שתופעל על דוגמת הטסט x (בננה במקרה המתואר). – הפעלה של פונקציה זו על שאילת טסט x. המאמר טוען שהפרמטרים האלו לא תלויים בשאילת הטסט x עצמו אלא רק ב- S (במאמר זה מנוסח בצורה מתמטית יפה שמאוד אהבתי). ההשערה הזו היא לא לגמרי טריוויאלית כי בארכיטקטורת הטרנספורמרים הייצוג של דוגמאות מתויגות S תלוי גם בשאילתה x.
המאמר מראה שב- ICL ניתן להגיע להפרדה כזו בין ייצוג המשימה (הנגזר מ- S) וייצוג השאליתה x. אוקיי, אז מה זה הפרמטרים האלו שמחושבים רק על דוגמאות S? המאמר טוען הם בעצם הפלטים של שכבה L של הטרנספורמר עבור הטוקנים של S כאשר L אינה השכבה האחרונה של מודל השפה. פרמטרים אלו מגדירים(דרך הזנה) לפונקציה שהיא הפעלה של השכבות הנותרות על פלט זה (= ייצוג המשימה) וגם על השאילתה x.
איך הם בדקו זאת? אוקיי, השאילתה מורכבת מגוף השאלה (בננה בדוגמה שלנו) ובסימן שאלה מאולתר (״->״ במקרה) שלנו המאותת למודל שפה שהוא צריך לפתור אותה. אז המחברים העתיקו את ייצוג של ״->״ בשכבה L עבור דוגמא לא קשורה x' ואז ממשיכים עם השאילתה המקורית לאחר מכן. המאמר מראה שעבור שכבה מסוימת L החלפה כזו לא מובילה לירידה ניכרת בביצועים(יחסית לייצוג של ״->״ הנבנה באופן רגיל) כלומר הפלט של שכבה L של מודל שפה עבור הטוקנים של S אכן לא תלויה בשאילתה x. מה שמעניין שעבור מודלי שפה בגדלים שונים L האופטימלי יצא בערך 15. מאמר די מעניין שנותן הסבר מסקרן למה ואיך ICL עובד. יהיה מעניין לראות מה קורה במקרים שמודל שפה נכשל ב-ICL אם מופעל בצורה הרגילה. האם ההפרדה הזו תישמר?

A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
https://huggingface.co/papers/2310.16656

אוקיי, מכיוון שהסקירה הזו היא סקירה של שבת, אז היא (הסקירה) הולכת להיות יותר קלילה ויותר קצרה מהרגיל. אחרי שאתמול סקרנו מאמר על מודלי שפה היום חוזרים למודלי דיפוזיה. המאמר המסוקר מציע שיטה די פשוטה לשיפור של מודל דיפוזיה טקסטואלי ההופך תיאור טקסטואלי לתמונה. המודל המשופר מצליח לייצר תמונות מתאימות יותר לתיאור הטקסטואלי בצורה מדויקת יותר. השיטה המוצעת מכילה 3 שלבים:
- גנרוט של 10K תמונות איכותיות ממודל דיפוזיה רגיל (aesthetics score ≥ 5.0, pwatermark < 0.5 etc). מודל דיפוזיה רגיל נבחר כמובן Stable Diffusion.
- כיול של מודל היוצר כותרת לתמונה (PaLi). כדי לכייל מודל captioning המחברים ביקשו ממתייגים אנושיים לתייג 100 תמונות ולתת לכל אחת 2 כותרות: אחת קצרה ותמצותית והשנייה ארוכה יותר אך עדיין מדויקת. לאחר מכן מודל ה-captioning כויל עם הדאטהסט הזה
- מפעילים את PaLi על הדאטהסט מהשלב הראשון ומכיילים SD על הדאטה הזה.
זהו זה – כך מקבלים מודל דיפוזיה משופר. הבטחתי לכם קל וקצר וקיימתי.

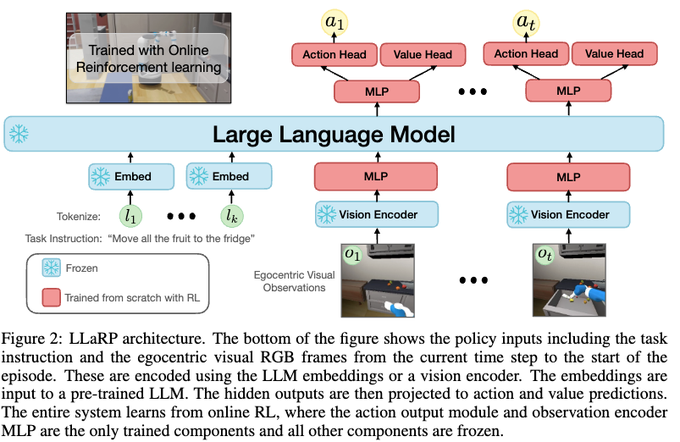
Large Language Models as Generalizable Policies for Embodied Tasks

על למידה באמצעות החיזוקים(reinforcement learning) שמעתם כבר? על מודלי שפה בטח שמעתם, נכון? אז היום אנחנו נדבר על השידוך ביניהם. אזכיר ש-RL היא למעשה משפחת שיטות המאפשרות לאמן מודל on-the-fly. כלומר תוך כדי אימון המודל ניתן ליצור דאטה כל פעם שהמודל מתאמן ולהמשיך לאמן עליו (יש גם offline RL שמאמן על דאטה סטטי).
באמצעות מודלי RL ניתן לאמן בין השאר רובוטים, רכבים אוטונומיים, מודלים להתמודדות עם איומי סייבר. לאחרונה יצאו כמה שיטות לאימון מודלי שפה באמצעות טכניקה שנלקחה מעולם ה-RL הנקראת RLHF. ה-ChatGPT המפורסם אומן תוך שימוש בטכניקה זו. המאמר המסוקר נשאלת השאלה האם ניתן לאמן רובוט לבצע פעולות מורכבות באמצעות מודלי שפה? מתברר שהתשובה לשאלה הזו היא כן.
המאמר לוקח מודל שפה מאומן (עם משקלים מוקפאים) ובנוסף מודל ויזואלי (מוקפא גם כן) ורותם אותם למשימת אימון זו. למשל ניתן לאמן רובוט לבצע פקודה הבאה: ״קח תפוח, בננה ולמון ותשים אותם יחד למקרר״. הגישה המוצעת היא די פשוטה. קודם כל לוקחים פקודה בשפה טבעית ובונים את השיכון (embedding) שלה באמצעות llm. בנוסף בכל שלב (נגיד אחרי כל תמונה של רובוט) מצלמים את הסביבה ומעבירים את התמונה דרך מודל ויזואלי כדי לקבל שיכון של התמונה. את ייצוג התמונה מעבירים דרך MLP מאומן(fully connected). לאחר מכן לוקחים את ייצוג הפקודה וייצוג של כל התמונות שנבנו (אחרי ה-MLP) ומכניסים את הוקטורים האלו לאותו מודל שפה(כאילו שהם טוקינם).
ביציאה ממודל השפה מקבלים את הייצוגים ההקשריים של הטוקנים הויזואליים (תמונות). לכל טוקן ויזואלי כזה מוסיפים עוד MLP מאומן בעל שני ראשים: אחד לחישוב הפעולה הבאה והשני לחישוב פונקציית ה-value (המשערת עד כמה המצב שהרובוט נמצא בו הוא מוצלח ביחס למשימה שהוא צריך לבצע). בשלב האחרון מאמנים סוכן (רובוט) לבצע את הפעולות האופטימליות בהתבסס על ייצוג הפקודה ועל ייצוגי התמונות של המצבים הקודמים תוך שימוש באיזה מודיפיקציה של PPO (proximal policy optimization הנקרא DD-PPO. פונקציית תגמול כמובן קשורה להצלחה בביצוע המשימה. כאמור מאמין שני ה-MLPs שדיברנו עליהם קודם. נציין שבעיית RL זו היא לא פשוטה בכלל עקב מורכבות המשימה והספרסיות של התגמול (מקבלים אותו רק בסוף אחרי הרבה שלבים). למרות זאת יש תוצאות יפות.