אתגר מערכות ההמלצה של jul – סיכום פתרון – מקום ראשון

אמנם, האתגר לא באמת נגמר כמו שצריך בגלל הוירוס. אבל עבדתי די קשה, אני מרשה לעצמי לסכם בכל מקרה!
לפני שבועיים Uri Goren פרסם את אתגר מערכות ההמלצה של jul.
אני מתעסק במערכות המלצה בתור (חצי) תחביב כבר כמעט שנה והרבה זמן חיפשתי תירוץ לצלול לעומק העניין.
אז למארגנים: תודה על הFOMO, אחלה תירוץ!
הבעיה: אנשים קנו מוצרים. אנחנו צריכים לאמר איזה מוצר הם יקנו בפעם הבאה.
הדאטה: טרנזקציות – אדם x קנה מוצר y בתאריך z.
ניקוד: אם קלענו למוצר אחד מתוך רשימת המוצרים העתידיים, האדם נספר לנו לחישוב הדיוק הסופי, שהוא לא יותר מאחוז האנשים בהם צדקנו.
עוד פרט חשוב: מספיק לנו לקלוע למוצר אחד. (ובדקתי את הפרט הזה דרך ההגשות ללידרבורד!)
ועוד פרט חשוב: אנחנו לא יודעים מה המוצרים! יש לנו רק id. זה חכם מצד המארגנים, היתי מנצל את זה לרעה אם זה לא היה ככה.
התחלתי לירות בייסליינים כבר בעשר הדקות הראשונות מפתיחת הטבלה.
הבייסליין הראשון כמובן: "תציע לכולם את המוצר הכי נפוץ".
השני היה: "תציע לכולם את המוצר הכי KNN.predict"
אחרי שניקיתי קצת, העפתי את העברית (כי זה דפק כל דבר אפשרי), העפתי את כל האנשים שאני יודע עליהם רק קניה אחת והגשתי את הבייסליין "תציע לכל אדם פשוט מה שהוא קנה ממנו הכי הרבה" ואת הבייסליין "תציע לכל אדם מה שכולם קונים הכי הרבה" והבייסליין "תציע לכל אדם מה שקונים ממנו הכי הרבה באותו החודש"
והכי חשוב,הרצתי את הבייסליין:
for cols_combination in כל_הקומבינציות(cols):
תציע לאותו אדם: df.groupby(cols_combination).agg(lambda x: x.value_counts().index[0])
שבאופן ממש מביך הביא אותי למקום הראשון בטבלה..
חצי שעה מפתיחת התחרות..
ואז התחלתי לעבוד באמת.
התוכנית? ממש פשוטה.
אני אאמן supervised learning במקום מערכת המלצה מהסיבה הפשוטה שאני לא מבין כלום במערכות המלצה.
אעשה מה שאני כן מבין בו: TimeSeries – לכל אדם אעקוב אחרי היסטורית הקניות שלו ואמדל את הבעיה כTime-series Classification Multilabel.
כלומר: נרוץ על היסטורית הקניה של אותו האדם ובכל שלב נאמן\נחזה לכל אחד מהמוצרים את ההסתברות שאותו אדם ירכוש בקניה הבאה את המוצר.
ככה גם יהיה לי Cross Validation שאוכל לעבוד איתו וגם אשאר בדיוק עם האתגר של "לכל אדם, האם הוא יקנה X בקניה הבאה?".
בסוף? פשוט אריץ argmax ואגיש.
מתחילים מההכי חשוב: Cross Validation
סקריפט הבדיקה של הCross Validation היה ממש פשוט: נסה לאמן LightGBM לפי איזו סכמת אימון. אם מה שאימנת יצא טוב: שמור.
כדי לבדוק את הcross validation scheme שלי פשוט בדקתי על הleaderboard כי היו אינסוף הגשות. אין כאן יותר מידי קסם.
ניסיתי GroupedKFold לפי אנשים \ מוצרים, K-Fold, StratifiedKFold, RepeatedStratifiedKFold וRepeatedStratifiedTimeSeriesSplit.
כמובן שRepeatedStratifiedTimeSeriesSplit ניצח כי זאת בעית TimeSeries. בכל מקרה רציתי לבדוק את כל שאר השילובים האפשריים של זה בשביל הספורט (כבר אמרתי שאין לי הרבה ניסיון במערכות המלצה, רציתי ללמוד בעצמי!)
*חדי העין ישימו לב שאין RepeatedStratifiedTimeSeriesSplit בsklearn והיתי צריך לממש את זה לבד.זה היה ממש לא נעים, תודה ששאלתם.
אותי אישית הפתיע במיוחד שGroupedKfold לפי אנשים \ מוצרים לא עבד טוב.
אפילו כשבמקום LGBM, אימנתי רשת על כל הדאטה ועשיתי לה fine-tuning לפר אדם \ פר מוצר \ פר אדם X מוצר (הגשתי את כל האופציות).
מה שעבד בסוף הכי טוב היה מודל שרואה את כל הדאטה וגם מקבל כאינפוט מי האדם המבצע את הרכישה. אני לא יודע למה אבל משום מה זה יצא הכי טוב. אני חושד בזה קשות עד עכשיו.
הסטאפ עצמו: GroupBy של כל הטרנזקציות לפי רכישהxאדםxתאריך (תודה רבה שזה לא חח"ע לorder_id דרך אגב), one-hot לכל המוצרים והמחלקות שלהן הם שייכים. כל זה כפול כמות הרכישה מכל מוצר בכל רכישה.
ואז shift לרכישה הבאה בשביל התיוג. שוב, הסטאפ הוא לחזות בכל רכישה את רשימת המוצרים של הרכישה הבאה.
היה מאד מפתיע בעיניי לראות שאפשר להגיע ל24% דיוק על ידי הסתכלות היסטורית של רכישה אחת אחורה בלבד (סתם LightGBM מכל רכישה לאחת הבאה בלי להפעיל את המוח בכלל).
התחלתי לעשות את הדבר ההגיוני שהוא לאמן רשת אחת עם multi-output לכל המוצרים.
לא הלך.
אז ניסיתי את כל הטריקים שבספר: גם unsupervised-pretraining, גם auto-encoderים, גם BERT עם הmasking וגם סתם רשת supervised.
אפילו שלפתי את הנשק הסודי: רשתות על גרפים.
התחלתי לעשות Reinforcement Learning לScore בטבלה כי המארגנים היו נחמדים והחזירו אותו בכל Submission.
ואז המארגנים שמו לב והפכו אותו לרנדום.
סבבה? סבבה.
כתבתי סקריפט שמפרסר את הHTML של העמוד ומוציא את הניקוד האמיתי שלי.
ואז היוזר Yam Peleg קיבל באן 🙁
אז פתחתי את Yam Peleg v2.
כתבתי סקריפט שמגיש בProxy מIPים שונים לטבלה ואז מפרסר את העמוד כדי להוציא את התוצאה האמיתית והגשתי מ7 יוזרים שונים!
ואז עשיתי Reinforcement Learning לטבלה! זה אפילו הסתדר טוב עם הA3C כשזה הגיש במקביל מכמה יוזרים לכמה סביבות!
אבל..
כלום לא עקף "תמליץ לכולם את מה שהם קונים הכי הרבה וזהו".
האם יכול להיות שMachine Learning לא עובד?!
אין סיכוי. הגיע הזמן להעלות את רמת האלימות.
מודל שונה לכל מוצר:
או בשפה פשוטה: "בהנתן כל מה שקנית אי פעם, מה ההסתברות שתקנה רוטב טריאקי בפעם הבאה שתזמין מהסופר?" (כמובן ש100% כי זה טעים חבל על הזמן)
רגע רגע! אבל רק רוטב טריאקי. המודל הזה לא חוזה שום דבר אחר. הוא רק מודל שמומחה בלחזות רטבי טריאקי. לא אכפת לו משום דבר אחר. כלום כלום.
להלן הפיצ'רים שכן עבדו:
פיצ'רים של זמן:
הפשוטים:
יום, חודש, שנה – l_month, l_day, l_year
הפשוטים אחרי שחושבים על זה רגע:
יום חודש שנה בתאריך עברי – h_day, h_month, h_year
פיצ'רים כדי לתפוס קניות לסופש:
האם יום ראשון\שישי\שבת? is_sunday, is_saturday, is_friday, is_weekend
אחרי הבנתי משהו חשוב, אנשים קונים שונה לארוחות חג! הוספתי מרחק מכל אחד מהחגים היהודים, נוצרים, מוסלמים, דרוזים בימים \ חודשים (חשדתי, חודשים כן הוסיף לתוצאות).
ועוד טריק: סדרת מרחקים בזמן בין כל ההזמנות של אותו האדם. ממנה פשוט חילצתי את כל הסטטיסטים שיש בפנדס. מיותר לציין שגם הוספתי לכל הזמנה שורת "מרחק בימים מההזמנה הקודמת" – כדי מחזוריות הזמנות.
פיצ'רים נצברים:
לכל אדם, לכל מוצר:
1. סכום\ממוצע מצטבר\stdמצטבר\ספירת מופעים\הפעמים שכל אדם קנה כל מוצר.
2. סכום המינימומים\מקסימום\מופעים\מכפלת כמות ברכישה\ממוצע שכל אדם קנה כל מוצר.
פיצ'רים time-series analysis:
חלון נע עם:
מינימום\מקסימום\ממוצע\סטיית תקן.
חלוקת מינימום במקסימום.
הפרש בין מינימום למקסימום.
ערך מוחלט של מינימום.
ערך מוחלט של מקסימום.
ערך מוחלט של מינימום + ערך מוחלט של מקסימום \ 2.
ולכל אחד מהפיצ'רים האלה: הפיצ'ר <מינוס> הערך בכל נק' בזמן.
פיצ'רים פר יוזר:
מספר מופעים.
יום\חודש\שנה קניה ממוצע\חציון\שכיח (הפכתי לקטגוריאלי).
ממוצע\חציון של מרחק הקניה מכל החגים של כל הדתות.
הוספתי גם groupy עם כל הסטטיסטים שיש בפרנדס וחילקתי\חיסרתי סטטיסטיים שהגיוני לעשות את זה בהם לכל רכישה.
פי'צרים פר מוצר:
ספירת מופעים.
ספירת מופעים groupby כל הפיצ'רים שמתארים תאריכים\זמן.
הפיצ'רים שלא עבדו:
יש עוד הרבה הרבה מאד פיצ'רים שלא עבדו, הרצתי ברוטפורס חילוצי פיצ'רים.
רובם המוחלט לא שינה כלום.
טובב… עכשיו נשאר רק איכשהו לייצר את כל זה לכל הדאטה.
הרצתי כמה Benchmarkים והגעתי למסקנה שבתוך 17 שעות אצליח לייצר את כל הפיצ'רים לכל קומבינציית אדםXמוצר על שרת עם 64 מעבדים.
מפה לשם, מצאתי את עצמי לאחר שבוע ויומיים עדיין ישן עם אטמים כי את הצרחות של השרת שמעו דרך הקירות ואת הויברציות של המאווררים הרגישו דרך הרצפה. אני עדיין מופתע שהשכנים לא אמרו מה דעתם על האתגר של jul.
אחרי התקופה המייגעת הצלחתי סוף סוף להכפיל את הגודל של הדאטהסט פי 60,000~. מקובץ csv במשקל 7 מגהבייט הגענו עכשיו לnpy. בגודל 400GB.
עכשיו רק נשאר למצוא דרך לדחוף את כל הבלאגן הזה לאיזה GPU וניצחתי.
אבל לצערי הרב את הקלאסטר האמיתי שלי לא הספקתי לקחת איתי לבידוד. נאלצתי להתפשר ולעבוד עם מה שיש לי בבית – 15 GPUs וכמה מאות בודדות של מעבדים (פוסט על זה בקרוב).
כל זה זה כמובן לא מספיק כדי להריץ אפוקים של 400GB עם MultiGPU. גם אם אני אמצא איזה טריק להריץ אותם על כמה מחשבים דרך הרשת המעפנה שיש לי בבית בזמן סביר.
נשאר רק דבר אחד שאפשר לעשות בסיטואציה: לאמן מודל לכל קומבינצית אדםXמוצר שידע בהינתן כל היסטורית הקניה של אותו האדם האם הוא הולך לקנות בגיחה הקרובה לסופר רוטב טריאקי.
טריוויה: כן ניסיתי לממש איזשהו מאמר שדיבר על Gradient Boosting Multilabel וזה לא עבד טוב.
האימון:
לפני הכל, צריך להדגיש עד כמה זה כבד חישובית: כדי לייצר פרדיקציה שרואה את כל המוצרים היתי צריך לאמן מודל לכל מוצר -> מעל 4000 מודלים.
וזה רק לפרדיקציה אחת! זה עוד לפני חיפוש היפרפרמטרים או אנסמבל מכל צורה.
אז.. בסוף אימנתי די הרבה מודלים לכל הסיפור.. התחלתי בLightGBMים כי הם הכי פשוטים ועובדים טוב בלי יותר מידי משחקי פרמטרים.
אימנתי באיזור 200,000 ואז התחלתי להוסיף מודלים מכל מיני סוגים לאנסמבל.
בהתחלה הוספתי כמובן catboostים וxgboostים: עוד כמה עשרות אלפים.
אחרי זה בעזרתו של Elad Dvash, מימשנו 19 מאמרי מערכות המלצה [1][2][3][4][5][6][7][8][9][10][11][12][13][14][15][16][17][18][19] ולקחנו מהם חלקים מפה ומשם שנראו לנו רלוונטים.
חדי העין ישימו לב שלחלק גדול מהם יש מימושים בDeepCTR. מימשנו את כולם מחדש בעצמינו כי החבילה הזאת במקרה הטוב Over מהונדסת סתם ובמקרה הרע פשוט ממומשת לא נכון.
חשוב לציין שמצאנו מימושים כן טובים להרבה מאמרים על ידי חיפוש קטעי קוד בגיטהאב. יש הרבה תיקונים ומימושים טובים יותר לDeepCTR אבל הם של חבר'ה מסין שאין להם טיפה של אנגלית בריפו. אפשר למצוא אותם על ידי חיפוש קוד.
בכל מקרה, השתמשתי במימושים שלנו ועשיתי על על חלקי הרשתות מהמאמרים חיפוש ארכיטרטורה מטורף כדי למצוא את רשת ההמלצה האולטימטיבית.
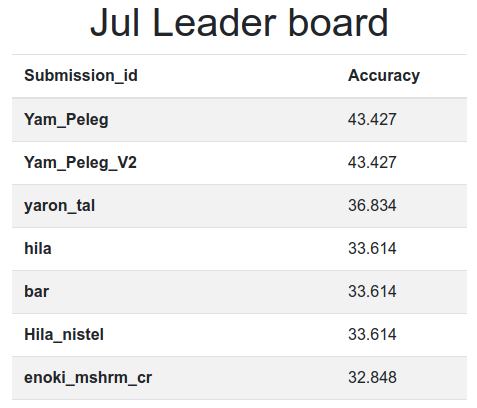
התוצאות? בתמונה..
[1] [CIKM 2015]A Convolutional Click Prediction Model
[2] [ECIR 2016]Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction
[3] [ICDM 2016]Product-based neural networks for user response prediction
[4] [DLRS 2016]Wide & Deep Learning for Recommender Systems
[5] [IJCAI 2017]DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
[6] [arxiv 2017]Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction
[7] [ADKDD 2017]Deep & Cross Network for Ad Click Predictions
[8] [IJCAI 2017]Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
[9] [SIGIR 2017]Neural Factorization Machines for Sparse Predictive Analytics
[10] [KDD 2018]xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
[12] [arxiv 2018]AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
[13] [KDD 2018]Deep Interest Network for Click-Through Rate Prediction
[14] [AAAI 2019]Deep Interest Evolution Network for Click-Through Rate Prediction
[15] [arxiv 2019]Operation-aware Neural Networks for User Response Prediction
[16] [WWW 2019]Feature Generation by Convolutional Neural Network for Click-Through Rate Prediction
[17] [IJCAI 2019]Deep Session Interest Network for Click-Through Rate Prediction
[18] [RecSys 2019]FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
[19] [arxiv 2019]FLEN: Leveraging Field for Scalable CTR Prediction


