Identifying Mislabeled Data using the Area Under the Margin Ranking (סקירה)

סקירה זו היא חלק מפינה קבועה בה אני סוקר מאמרים חשובים בתחום ה-ML/DL, וכותב גרסה פשוטה וברורה יותר שלהם בעברית. במידה ותרצו לקרוא את המאמרים הנוספים שסיכמתי, אתם מוזמנים לבדוק את העמוד שמרכז אותם תחת השם deepnightlearners.
לילה טוב חברים, היום אנחנו שוב בפינתנו deepnightlearners עם סקירה של מאמר בתחום הלמידה העמוקה. היום בחרתי לסקירה את המאמר שנקרא:
Identifying Mislabeled Data using the Area Under the Margin Ranking
פינת הסוקר:
המלצת קריאה ממייק: כמעט חובה – (לא חובה אבל קרוב לזה 😉 ).
בהירות כתיבה: גבוהה
רמת היכרות עם כלים מתמטיים וטכניקות של ML/DL הנדרשים להבנת מאמר: היכרות בסיסית עם מושגי יסוד של הלמידה העמוקה (בעיקר אלו הקשורות לאימון של רשתות נוירונים).
יישומים פרקטיים אפשריים: אופטימיזציה של תהליך אימון של רשתות נוירונים עי״ זיהוי של דוגמאות מתיוגות תוך כדי האימון.
פרטי מאמר:
לינק למאמר: זמין להורדה.
לינק לקוד: כאן.
פורסם בתאריך: 23.12.2021, בארקיב.
הוצג בכנס: NeurIPS 2020.
תחומי מאמר:
- זיהוי דוגמאות בעלות לייבלים שגויים בתהליך אימון של רשתות נוירונים.
כלים מתמטיים הסימונים:
- לוגיטים (logits): פלט של השכבה האחרונה של רשת סיווג (לפני הנרמול softmax/sigmoid).
תחומים בהם ניתן להשתמש בגישה המוצעת:
- למידה semi-supervised.
- אוגמנטציה של דאטהסטים.
תמצית מאמר:
אחד הגורמים המרכזיים שמשפיעים על ביצועים של רשתות נוירונים הינו איכות של הדאטה סט שעליו הרשת מאומנת. בחלק לא מבוטל של מדאטה סטים הלייבלים הינם "חלשים" (לא מדויקים) כי התיוג בוצע דרך שימוש במשתני פרוקסי או דרך גירוד דפי האינטרנט. זיהוי דוגמאות עם לייבלים מוטעים עשוי לשפר את יכולת ההכללה של רשת וגם תוריד את רמת הזיכרון שלה (memorization).
מכיוון שרשתות נוירונים העכשוויות הינן בעלות מספר גבוה של פרמטרים, נדרשים דאטה סטים גדולים מאוד בשביל לאמן אותן. עבור רוב הדאטה סטים לא ניתן (או מאוד יקר) לעבור עליהם במטרה לזהות דוגמאות המתויגות בצורה שגויה. עקב כך יש צורך בפיתוח גישות אוטומטיות (ללא התערבות בני אדם) לזיהוי של דוגמאות כאלו.
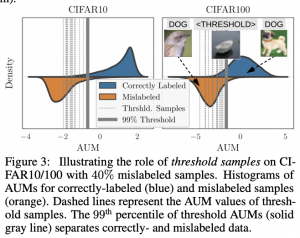
המאמר מציע שיטה לזיהוי אוטומטי (ללא התערבות אנושית) של דוגמאות עם לייבלים שגויים במהלך אימון של רשתות נוירונים. השיטה מנצלת את המידע על לוגיטים (logits) של דוגמאות לאורך אימון הרשת לזיהוי של דוגמאות עם לייבלים מוטעים. המטריקה שהם משתמשים בה נקראת שטח מתחת השוליים (area under the margin – AUM). יותר קונקרטית, לדוגמא נתונה AUM מודד את ההפרש הממוצע על פני כל האפוקים בתהליך אימון הרשת, בין ערכי הלוגיט של הקטגוריה המתאימה ללייבל שאיתו הדוגמא מתויגת, לבין המקסימום של כל ערכי הלוגיטים של הקטגוריות האחרות.
פינת האינטואיציה: עבור דוגמאות מתויגות נכון הפרשים אלו אמורים לעלות לאורך האימון כי יכולת ההכללה (הנבנית על סמך דוגמאות עם אותו לייבל) של הרשת עולה ככל שהאימון מתקדם. לעומת זאת בדוגמאות המתויגות בצורה שגויה הרשת לא מצליחה לנצל את העלייה ביכולת הכללה שלה ו- AUM לא "מתרומם" ככל שהאימון מתקדם. הסיבה לכך טמונה בעובדה שהרשת "רואה" שדוגמא מתויגת עם לייבל l_wrong, דומה לדוגמאות הנושאות לייבל אחר (הנכון) l_cor ומנסה לדחוף את הלוגיט המתאים ל- l_cor למעלה שגורם לירידה במרג'ין של הדוגמא. אז באופן אינטואיטיבי AUM עבור דוגמאות "נכונות" אמור להיות יותר גבוה מזה של הדוגמאות "הלא נכונות".
המאמר מציע לנצל את האינטואיציה הזו ולזהות דוגמאות שגויות על בסיס ה- AUM שלהם. מכיוון שאנו לא יודעים מה האחוז של דוגמאות "לא נכונות" בדאטה סט נשאלת השאלה: איך נבחר את ערך הסף של AUM המבדיל בין דוגמאות נכונות ללא נכונות. המאמר מציע לבנות קטגוריה מלאכותית מתוך הדאטה סט שעל בסיס ה- AUM שלה הסף הזה נבחר.
הסבר של רעיונות בסיסיים:
כמו שכבר אמרנו עבור דוגמא x ואפוק t, השול (margin) מחושב כהפרש בין הלוגיט של הלייבל שאיתו הדוגמא מתויגת לבין המקסימום בין הלוגיטים של כל הלייבלים האחרים. AUM עבור דוגמה x מוגדר כממוצע של הפרשים אלו על פני כל האפוקים. אתם תשאלו – מה הקשר של הממוצע הזה לשטח מתחת לגרף של מרג'ינים: כדי להבין זאת מספיק להביט באיור המצורף: שטח מתחת לשול משוערך ע" הממוצע של השולים על פני האפוקים של אימון (אלו שעדיין לא הספיקו לשכוח חדו"א 1 יכולים לראות שהממוצע זה הינו סכום דרבו של הפונקציה מוגדרת על האפוקים והערכים שלה הם המרג'ינים). קל לראות שאם המרג'ין של דוגמא הינו מספר חיובי גבוה אז הרשת מצליחה לחזות נכון את הלייבל של דוגמא זאת. לעומת זאת השול שלילי גבוה מצביע על כך שהרשת רואה את הדוגמא כדומה לדוגמאות המתויגות עם לייבל אחר (החיזוי שלה יהיה כמובן לא נכון עבור דוגמא זו).

הערה: מספר עבודות הוכיחו שגודל ממוצע של מרג'ין מהווה אינדיקציה ליכולת הכללה של הרשת: כלומר ככל שהשול הממוצע גבוה יותר, יכולת הכללה של הרשת עשויה להיות טובה יותר.
אז אחרי שאנו מבינים ש- AUM-ים של דוגמאות "נכונות" צריכים להיות יותר גבוהים מאשר אלו של דוגמאות מתויגות בצורה שגויה, ניתן רק לבחור את הסף המבדיל ביניהם. במילים אחרות אנו רוצים להבין מהו הערך של thr_aum שכל דוגמא עם AUM קטן מ- thr_aum, תוכרז כנושאת לייבל שגוי. מכיוון שאנו לא יודעים מלכתחילה מה אחוז הדוגמאות השגויות, בחירת thr_aum לא נכונה עלולה להוביל ל"פסילה" של דוגמאות נכונות (אם thr_aum גבוה מדי) או לא אי זיהוי של דוגמאות שגויות (אם thr_aum נמוך מדי).
בשביל לתת מענה לסוגייה זו, המאמר מציע טריק אלגנטי: הוא מציע לקחת (לבחור באקראי) חלק מהדוגמאות (סט של דוגמאות אלו יסומן כ- D_thr) ולתייג אותן עם לייבל מומצא l_dum. מאחר והלייבל l_dum לא באמת קיים כל דוגמא ב D_thr אפשר לראות בתור דוגמה עם לייבל לא נכון. לכן ניתן לנצל את ה- AUM-ים שלהם כדי לקבוע את הערך של thr_aum. בעצם מאמנים את הרשת על איחוד של D_thr ושאר הדוגמאות D_rest מהדאטה סט המקורי D ובוחרים את thr_aum בתור ערך האחוזון 99(הייפר פרמטר של האלגוריתם) של AUM-ים של הדוגמאות מ- D_thr. דרך אגב המאמר טוען כי האלגוריתם די רובסטי להייפר פרמטר הזה.
הערה: השיטה המתוארת כמובן לא מזהה דוגמאות "לא נכונות" מהסט D_thr אז מריצים אותו עוד פעם עם סט D_thr אחר שלא מכיל את הדוגמאות שנבחרו להיכלל בו באיטרציה הקודמת.
הישגי מאמר:
המאמר מראה את היעילות של השיטה שלהם בשתי דרכים:
- בדיקה של איכות הזיהוי של דוגמאות מתויגות בצורה שגויה על דאטה סטים מלאכותיים שנוצרים עי" שינוי של לייבלים על אחוז מסוים של דוגמאות. נגיד הם לקחו CIFAR100 ושינו לייבלים בצורה אקראית לאחוז מסוים של דוגמאות. הם הראו שהשיטה שלהם מצליחה להשיג ביצועים יותר טובים (מבחינת precision ו- recall) מהשיטות לזיהוי דוגמאות שגויות כמו: (DY-Bootstrap (BMM), DY-Bootstrap (GMM ו- INCV. ההשוואות בוצעו על דאטה סטים TinyImageNet ו- CIFAR10/100. שתי הראשונות הן למעשה אותה שיטה המנסה להתאים התפלגות (הראשונה עם גאוסיאנים והשנייה עם בטה) עם שני מודים עבור סטטיסטיקה של ערכי הלוס של הרשת (המוד הראשון ממדל את הדוגמאות הנכונות והשני ממדל את הדוגמאות השגויות).
- בחינה מידת שיפור בביצועים על דאטה סטים אחרי ההורדה של הדוגמאות השגויות שזוהו באמצעות AUM. גם כאן הם הראו שיפור בביצועים של יחסית למספר שיטות מתחרות בחינת שגיאת טסט ממוצעת. ההשוואות בוצעו על מספר דאטה סטים: WebVision50 ,Clothing100K ,CIFAR10 CIFAR100 ,Tiny ImageNet .ImageNet
הערת סיום: הם מציינים שהשיטה שלהם עובדת טוב כאשר הדוגמאות השגויות לא נבנות בצורה ״זדונית״ אלא נוצרות כתוצאה של טעויות אנוש. למשל אם מישהו בצורה מכוונת יסמן את כל תמונות הכלבים כציפורים, לא יהיה ניתן לזהות אותן אם AUM (האמת שאני מתקשה לחשוב על שיטה שלא משתמשת במידע נוסף על לייבלים או בדאטה חיצוני תצליח לעשות זאת).
נ.ב. מאמר נחמד עם רעיון מאוד אינטואיטיבי ומובן שבאופן מפתיע מצליח לנצח שיטות מורכבות יותר. אני מחכה לראות הכללה של גישה זו למשימות יותר מורכבות מסיווג….
#deepnightlearners
הפוסט נכתב על ידי מיכאל (מייק) ארליכסון, PhD.
מיכאל עובד בחברת סייבר Salt Security בתור Principal Data Scientist. מיכאל חוקר ופועל בתחום הלמידה העמוקה, ולצד זאת מרצה ומנגיש את החומרים המדעיים לקהל הרחב.


