DiffusionDet: Diffusion Model for Object Detection, סקירה

סקירה זו היא חלק מפינה קבועה בה אנחנו סוקרים מאמרים חשובים בתחום ה-ML/DL, וכותב גרסה פשוטה וברורה יותר שלהם בעברית. במידה ותרצו לקרוא את המאמרים הנוספים שסיכמתי, אתם מוזמנים לבדוק את העמוד שמרכז אותם תחת השם deepnightlearners.
לילה טוב חברים, היום אנחנו שוב בפינתנו deepnightlearners עם סקירה של מאמר בתחום הלמידה העמוקה. היום בחרתי לסקירה את המאמר שנקרא:
DiffusionDet: Diffusion Model for Object Detection
פינת הסוקר:
המלצת קריאה מאברהם ומייק: מומלץ לעוסקים בתחומחי זיהוי אובייקטים ולאוהבי מודלי דיפוזיה
בהירות כתיבה: בינונית פלוס
ידע מוקדם:
-
- הבנה טובה בעקרונות של DDPM (מודלי דיפוזיה)
- היכרות עם מושג יסוד בתחום זיהוי האובייקטים
יישומים פרקטיים אפשריים: משימות שבהן נדרשת היכולת לזהות אובייקטים בתמונה
פרטי מאמר:
לינק למאמר: זמין להורדה
לינק לקוד: זמין להורדה
פורסם בתאריך: 17.11.22, בארקיב.
הוצג בכנס: טרם ידוע
תחומי מאמר:
- זיהוי אובייקטים בתמונות
- מודלי דיפוזיה (DDPM)
מבוא:
מודלי דיפוזיה (DDPM) הפכו לדבר החם בתחום Generative AI. מאז שפורסם המאמר "Diffusion Models Beat GANs on Image Synthesis" (שסקרנו אותו במדור זה) חברות וצוותי מחקר רבים פרסמו מודלים גנרטיביים, מבוססי DDPM, במגוון דומיינים (תמונות, אודיו, וידאו, מודלי 3D ועוד). מודלים אלו הפגינו ביצועים מרהיבים (DALLE-2, Imagen, Stable Diffusion, Make-A-Video) והצליחו ליצור פיסות דאטה חדשות באיכות מרשימה. רוב מודלי דיפוזיה שפותחו בשנתיים האחרונות היו מיועדים למשימות גנרטיביות שונות כאשר מספר מועט יחסית של מאמרים ניצלו את עוצמתם האדירה למשימות דיסקרימינטיביות כמו משימות סגמנטציה מסוגים שונים: semantic, instance and panoptic segmentation. לעומת זאת מודלי דיפוזיה לא נוצלו כלל למשימת זיהוי אובייקטים (לפחות ככה טוענים מחברי המאמר שנסקור). הסיבה האפשרית לכך נעוצה בעובדה שמשימות סגמנטציה דומות יותר למשימות גנרטיביות (מימד הפלט שווה למימד הקלט) מאשר למשימת זיהוי אובייקטים שמטרתן היא זיהוי סט של bounding boxes המתאימים לאובייקטים שיש בתמונה.
המאמר הנסקר מציע שיטה לזיהוי אובייקטים בתמונה המבוססת על עקרונות מודלי דיפוזיה. נזכיר כי מטרת המשימה כאן היא לזהות את מיקום האובייקטים ולסווג כל אחד מהם. מיקום של אובייקט מוגדר באמצעות Bounding Box (BB), ולכל BB שהמודל מספק מתווסף גם סיווג לאובייקט. BB הינו מלבן מוגדר על ידי רביעייה המורכבת מקואורדינטות של מרכז הלבן (שני מספרים) וגודל המלבן (שני מספרים גם כן).
בכדי להדגיש את החדשנות של המאמר יש להזכיר בקצרה את הגישות המקובלות בעולם של Object Detection: עד המצאת הטרנספורמרים היו שתי ארכיטקטורות שולטות (one stage and two stage detectors), ולאחר מכן הגיע לעולם גלאי מבוסס טרנספורמרים (DETR, שסקרנו אותו במדור זה), שהלך והשתכלל (סקרנו אחד השכלולים שלו גם כן). לכל אחת משלוש הגישות יש יתרונות וחסרונות, ורוב מוחלט של המאמרים החדשים היוצאים בתחום מתבססים על אחת מגישות אלה תוך ניסיון להגיע לביצועים טובים יותר על ידי הוספות ושינויים על גבי הרעיונות הקיימים. הצעה של מנגנון חדש לגמרי הוא דבר מאוד נדיר בתחום זה (ואחד כזה סקרנו לפני כחצי שנה), ועד כה עוד לא יצא רעיון חדש שיצר מספיק הד בכדי להוות תחרות אמיתית למנגנונים הקיימים. המאמר הנסקר מתיימר להציג מנגנון חדש לחלוטין, מבוסס מודלי דיפוזיה, והוא מנסה להתגבר על אחד מהקשיים הבולטים שיש בשיטות הקיימות: התמודדות עם מספר משתנה של אובייקטים בכל תמונה. ישנן גישות המכריחות מספר קבוע של אובייקטים במוצא, ואז מסננים אותם באמצעות מנגנון (Non Maximum Suppression(NMS. בדומה לכך, גישות מבוססות טרנספורמרים, כמו למשל DETR מגדירות מראש מספר קבוע של learnable queries, ומאפשרות קלאס של "no object" בכדי לסנן זיהויים של רקע. המאמר הנסקר מציע גישה, מבוססת מודלי דיפוזיה, המאפשרת לייתר את השימוש בשאילתות אלו שהופך את השיטה לנוחה עוד יותר.
הסבר על הרעיון העיקרי:
הרעיון המרכזי הוא די פשוט: בואו נתחיל מסט רנדומלי של BB ובתהליך הדרגתי נהפוך אותם ל-BB המתארים את האוייבקטים בתמונה. כמו במודלי דיפוזיה גנרטיביים אנו ״נרעיש״ את ה-BB האמיתיים של התמונה באופן הדרגתי במהלך התהליך הקדמי (forward process) ואילו המטרה של התהליך האחורי (backward process) היא ללמוד לנקות את הרעש מה-BB המורעשים בצורה הדרגתית גם כן. חשוב לשים לב שבשונה ממודלי דיפוזיה שמטרתם ללמוד לייצר תמונות מרעש, כאן התמונה עצמה אינה מורעשת בתהליך האימון, אלא מה שמתווסף בכל שלב לתמונה זה עוד BB, שהם למעשה "רעש" ביחס ל-BB האמיתיים. התמונה הבאה ממחישה את הרעש המתווסף בכל צעד, ואת השוני בין הרעש הזה (שהוא למעשה הוספת BB) לבין הרעשה של כל התמונה כפי שמתבצע בתהליך דיפוזיה שמטרתו לאמן מודל לייצר תמונה חדשה:

Noise-to-Image vs. Noise-to-Box
כעת נספק הסבר מפורט יותר איך מאמנים ומבצעים הסרה (inference) עם DiffusionDet.

אימון של DiffusionDet:
כאמור האימון כולל ״הוספת רעש״ הדרגתית ל-BBs שיש בתמונה (תהליך קדמי) כאשר הרשת מאומנת לחזות את הדאטה של האיטרציה הקודמת. אבל להבדיל ממודלי דיפוזיה במשימות הגנרטיביות, שמאומנים לחזות את הרעש שהתווסף באיטרציה t (ששקול לחזוי הדאטה של איטרציה t-1, ראה סקירה זו להסבר מפורט יותר), הכותבים מאמנים את הרשת לחזות את הדאטה המקורי x0 (כלומר BB האמיתיים). עקב כך הגנרוט מתבצע באופן שונה ממודלי הדיפוזיה הקלאסים (נרחיב על כך בפרק הבא).
האימון מתחיל מהוספה של BB רנדומליים ל-BB האמיתיים של התמונה כך שהמספר הכולל של BB-ים יהיה שווה ל-Ntrain המוגדר מראש. לאחר מכן ה-BB-ים האמיתיים ״מורעשים״ באמצעות scaling של צלעותיהם עם מקדם (1 ,0) ∋ βt והוספת רעש גאוסי בעל שונות (1+ βt-). יש לשים לב שכאן, להבדיל ממודלי הדיפוזיה הסטנדרטיים, הרעש המתווסף הינו תלוי בדאטה המקורי x0 (כלומר ב- BB-ים האמיתיים). עקב כך תהליך דיפוזיה מאבד את תכונה המקרוביות שלו:
p(xt | xt-1, x0 ) ≠ p(xt | xt-1)
תהליכי דיפוזיה מסוג זה נדונו במאמר "Denoising Diffusion Implicit Models (DDIM)". למרות העדר תכונת המקרוביות למודלים אלו אותה פונקציית המטרה כמו למודלי הדיפוזיה הסטנדרטיים לבחירה מסוימת של הייפרפרמטרי σt שלו. בנוסף לכך DDIM מאפשר דגימה יותר מהירה כאשר מגנרטים פיסות דאטה חדשות (ניתן ״לדלג״ על כמה איטרציות). במהלך האימון של DiffusionDet הרשת לומדת לחזות את הדאטה (BB-ים) המקורי x0 בכל איטרציה t במקום לחזות את הרעש שמתווסף באיטרציה t.
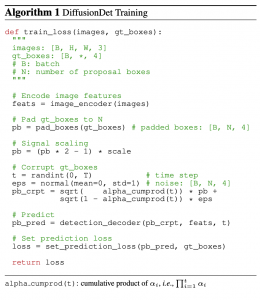
זיהוי אובייקטים עם DiffusionDet:
כדי לבצע זיוהי אובייקטים בתמונה נתונה מתחילים מ-Ntrain של BB-ים במיקומים ובגדלים אקראיים. לאחר מכן מפעילים את הרשת המאומנת לחזות את ה-BB המקוריים (התמונה עצמה היא אחד הקלטים למודל). בשלב הבא מפעילים את הגישה של DDIM כדי לשערך את ה-BB של האיטרציה הקודמת מהחיזוי של x0 מהשלב הקודם. לבסוף מבצעים ניפוי של BB-ים הנמצאים רחוק מה-BB-ים האמיתיים ומוסיפים במקומם BB-ים אקראיים. בשביל כך הכותבים מזהים BB-ים עם הציון (כנראה קרבה ל BB אמיתי הקרוב ביותר – לא צוין במאמר באיזו מטריקה משתמשים כאן) מתחת לסף קבוע מראש ומחליפים אותם באקראיים. הכותבים מציינים שאופן הסקה (inference) זה מאפשר לבצע זיהוי אובייקטים עבור מספר ה-BB שונים (Ntrain) ועבור מספר איטרציה שונות. עבור Ntrain קבוע ככל שמגדילים את מספר האיטרציות כך הביצועים של DiffusionDet משתפרים וזמן ה-inference עולה. ניתן לנצל את הטרייד-אוף הזה כדי לקבוע את הפרמטרים האופטימליים של DiffusionDet עבור משימה נתונה.

ניתוח תוצאות:
המחברים מספקים תוצאות המשתוות לשיטות SOTA ביחס לשני דאטהסטים, ועם מגוון backbones, כאשר בכל ריצה הם בוחנים את התוצאה אחרי איטרציה אחת, ארבע איטרציות ושמונה איטרציות. כמו כן, הם מספקים ablation study נרחב הבא לבחון שאלות כמו איזה מספר התחלתי של BB כדאי לבחור, כיצד לדגום את אותם BB, מספר איטרצות (ו-latency) לעומת accuracy ועוד.
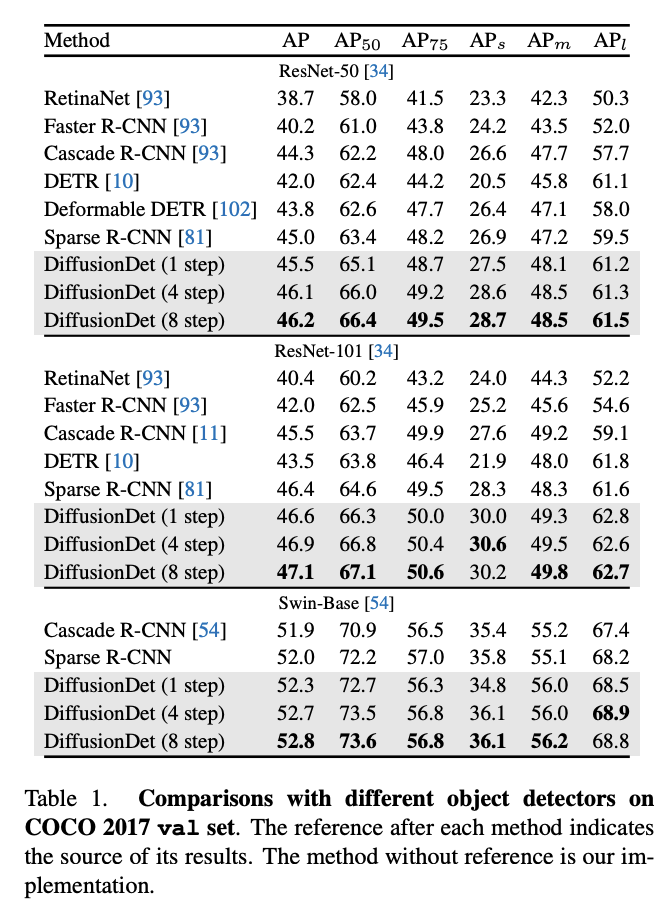
לסיום כדאי לעמוד בקצרה על היתרונות והחסרונות של שיטה זו לעומת המודלים הבולטים היום. כאמור בפתיחה, האינטואציה מאחורי השיטה הוא הרצון להמנע מהצורך להגדיר מספר קבוע של detections. כמו כן, אלגוריתם זה אינו מצריך post process כמו NMS, כיוון שהוא מספק מספר detections כמספר האובייקטים שהוא חושב שיש בתמונה. בנוסף, המימוש יחסית מאוד פשוט, ובהנתן משקולות מאומנות לביצוע משימת דיפוזיה, האימון עבור downstream task של זיהוי אובייקטים אינו מורכב. עם זאת, הרעיון אינו טבעי לבעיה, ומנסה להיעזר ב-feature maps שהמודל לומד בצורה עקיפה (על ידי refinement ל-BB). כמו כן, הוא איטי יותר מאלגוריתמים אחרים, וכנראה לא יוכל להתאים למכשירים הפועלים בזמן אמת.
הפוסט נכתב על ידי מיכאל (מייק) ארליכסון, PhD, Michael Erlihson ואברהם רביב.
מיכאל עובד בחברת הסייבר Salt Security בתור Principal Data Scientist. מיכאל חוקר ופועל בתחום הלמידה העמוקה, ולצד זאת מרצה ומנגיש את החומרים המדעיים לקהל הרחב.
אברהם סטודנט לתארים מתקדמים בתחום של Data Science ועובד בחברת סמסונג. מתעניין בלמידה עמוקה ובראייה ממוחשבת. מחבר ספר על למידת מכונה ולמידה עמוקה בעברית.


