לקט שבועי מתמלא של סקירות קצרות של #shorthebrewpapereviews, שבוע 26.08.23-01.09.23

26.08.23: Watch Your Steps: Local Image and Scene Editing by Text Instructions
https://arxiv.org/abs/2211.09800.pdf

מודלי הדיפוזיה לגמרי השתלטו כמעט על כל המשימות של הראייה הממוחשבת. למשל עריכה של תמונות (למשל להחליף ציפור בפרפר)בהתאם לתיאור טקסטאולי כבר מזמן עושים רק באמצעות מודלי דיפוזיה חזקים כמו InstructPix2Pix (IP2P). למרות התוצאות המדהימות עדיין יש אי התאמות בין התמונה הערוכה לבין המקורית. היום ב-#shorthebrewpapereviews נסקור מאמר שמנסה לתקן את אי דיוקים אלו בצורה די אלגנטית. בשלב הראשון המודל המוצע מאתר את מיקום הפיקסלים שאותם צריך לשנות(מסכה) ובשלב השני עורכים את התמונה רק באזורים של המסכה. כל זה נעשה באמצעות מודלי דיפוזיה באופן די אלגנטי. בשלב הראשון מרעישים את התמונה המקורית (עד רמת רעש מסוימת שהיא מהווה הייפרפרמטר חשוב מאוד) משתמשים במודל IP2P כדי לשערך את הרעש נוסף עבור ללא תופסת טקסט לעריכה ויחד איתו. כלומר במקרה הראשון אנו מפעילים מודל דיפוזיה סטנדרטי (ללא עריכה) ובמקרה השני כן עורכים את התמונה בהתאם לתיאור הטקסטואלי. לאחר מכן מחשבים את הערך המוחלט של ההפרש בין השערוכים אלו, מקצצים את החריגים (עם IQR עם מקדם 1.5). המסכה מקבלת ערך 1 (פיקסלים לעריכה) במקומות שההפרש הזה עולה על סף מסוים (הייפרפרמטר נוסף). בשלב השני מרעישים את התמונה (רמת הרעש עוד הייפרפרמטר). ואז באמצעות מסירים את הרעש עם מודל IP2P (עם תיאור טקסטואלי) באיזורים של המסכה ובכל האזורים האחרים עושים זאת עם מודל דיפוזיה רגיל (הטקסט המוסף הוא ריק). בנוסף המחברים מכלילים את הגישה שלהם ל-NeRF (ייצוג של מודלי 3D). בגדול עושים את מה שמתואר למעלה על views מכל הזווית תוך שמירה של קוהרנטיות ביניהם.

27.08.23: SeamlessM4T—Massively Multilingual & Multimodal Machine Translation
https://ai.meta.com/research/publications/seamless-m4t
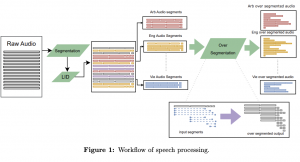
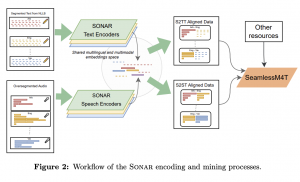
היום ב-#shorthebrewpapereviews נסקור מאמר מרשים מבית היוצר של מטה שיצא לפני כמה ימים. המאמר מציע מודל מולטימודלי שתומך בשני סוגים של דאטה בלבד: אותות קול (speech) ושפה. זה לא נשמע מרשים מדי עד שמבינים מה המודל הזה מסוגל לעשות עם שני סוגי הדאטה האלו. למעשה המודל מאפשר לבצע 4 פעולות: תרגום של אות קול משפת מקורה לשפה אחרת, תרגום של אות קול לטקסט בשפה אחרת, הפיכה של אות קול לטקסט בשפה אחרת ותרגום טקסטואלי רגיל. זה גם לא נשמע מרשים במיוחד בתקופתנו העמוסה במודלים עוצמתיים שיוצאים כמעט כל יום עד שמגלים ה- SeamlessM4T יודע לבצע את הפעולות האלו בלא פחות מ-200 שפות שונות כולל שפות די לא נפוצות כמו גאורגית וליטאית. כמו שכבר אמרנו בסקירות הקודמות הדבר החשוב ביותר במודלי מולטימודליים הוא מיפוי קוהרנטי של סוגי הדאטה השונים לאותו מרחב שיכון (embedding space). הקוהרנטיות כאן פירושה שפיסות דאטה מסוגים עם משמעות דומה יהיו קרובים במרחב הזה ואלו שמשמעותם שונים יהיו רחוקים זה מזה. מכיוון שהמבנה הפנימי של אות קול הוא מאוד שונה מטקסט הוא צריך לעבור עיבוד מקדים (preprocessing) לפני שמכניסים אותו לרשת הממפה אותו למחרב הזה. מכיוון שגלי קול בשפות שונות מבנה מאוד שונה בשלב הראשון מזהים את השפה (כאשר הקלט מכיל כמה שפות מפרקים אותו לסגמנטים שכל אחד הוא בשפה שונה). לאחר מכן לוקחים אות דיבור בכל שפה ועושים מה שנקרא oversegmegmentation שמשעומתה מספר חלוקות של האות לכמה סגמנטים שונים. ייצוגים אלו נכנסים לאנקודר של אותות קול שמאומן להפיק וקטור שיכון של אות קול. המאמר גם מאמן אנקודר לטקסט בצורה די סטנדרטית (אך לשפות מרובות). לאחר מכן מאמנים מודל הממפה שיכונים אלו למרחב ייצוג משותף ולאחר מכן מאמנים דקודר ההופך את ייצוג הזה לטקסט. בשלב האחרון מאמנים מודל נוסף ההופך את הטקסט הזה לאות קול. יש הרבה פרטים מעניינים על תהליך האימון שלא ניתן לכסותם בסקירה הקצרה הזו – ממליץ להעיף מבט.
28.08.23: Nougat: Neural Optical Understanding for Academic Documents
https://arxiv.org/abs/2308.13418.pdf
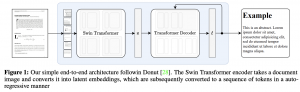
אתם בטח שמתם לב כי אני אוהב לקרוא מאמרים. יש מאמרים שלא פשוט להבין אותם ואז אני מתחיל לחפש מושגים שונים או איפה ובאיזה הקשר מופיעים כל מיני רפרנסים בקובץ של המאמר. זה כמובן אפשרי רק עבור מאמרים יחסית חדשים (ב 20 השנים האחרונות). במאמרים ישנים זה בעייתי כי הם פשוט מהווים צילום של המאמר. היום ב-#shorthebrewpapereviews סוקרים מאמר שלוקח מאמר מדעי שהוא לא בפורמט הנוח והופך אותו למסמך נוח לקריאה בכיף ולחפש שם כל מיני דברים. איך הם עשו זאת? מכיוון שהמסמך מגיע בתור תמונה בשלב הראשון צריך לבצע Optical Character Recognition או OCR. משימה זאת איננה פשוטה כי מאמרים לפעמים מכילים נוסחאות די מורכבות וסביר להניח ששיטות OCR קיימות די יתקשו להתמודד עם זה. המאמר מפתח מודל לזיהוי תוכן מהתמונה של מסמך בעצמו. המודל מורכב מאנקודר שמקבל את תמונת המאמר, עושה לו עיבוד מקדים (מוריד שוליים, הופך לאותו גודל וכדומה). לאחר מכן התמונה מחולקת לפאצ'ים זרים ומכניסה אותו לרשת הטרנספורמר מסוג Swin שמטרתו להפיק את הייצוג הלטנטי של תמונת המסמך. לאחר מכן ייצוג לטנטי זה מוזן לדקודר שהוא גם טרנספומר שמטרתו לפענח את המסמך ולהציג אותו בשפת markdown, שניתן להפוך אותה ל-pdf בקלות. הדאטהסט לאימון בנוי מהתמונות של מאמרים ומייצוגם בשפת markdown (למסמך קיים בצורה ״דיגיטלית״ ניתן לתרגם את ייצוג ה-tex של המסמך לשפת ה-markdown הזו). כמובן משתמשים במגוון אוגמנציות של תמונות המסמכים לאימון המודל שלהם כדי לשפר את יכולת ההכללה שלו. כמובן השיטה המוצעת עדיין מוגבלת ודורשת עיבוד מקדים לא קל של תמונות המאמרים אבל זו התחלה טובה.
29.08.23: Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Large Language Models
https://arxiv.org/abs/2305.16582.pdf
הסקירה נכתבה על ידי עדן יבין
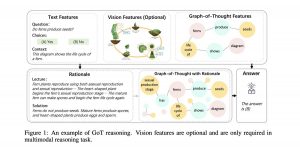
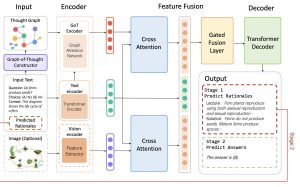
מנגנוני היגיון שונים עוזרים לסוכנים שלנו להבין משימות מורכבות ולבצע אותן בהצלחה. המנגנונים כוללים שיטות כמו שרשרת מחשבות (chain of thought) או עץ מחשבות אך מה עם גרף מחשבות? היום ב-#shorthebrewpapereviews. החוקרים טוענים שהדרך שלהם מבוססת על העובדה שאנשים לא חושבים בצעדים כגון בשרשרת אלא קופצים ״מקודקוד״ של מחשבה לקודקוד אחר. כך ניתן להרכיב מחשבות מורכבות ומגוונות יותר על ידי חיבור קשרים שונים בגרף. אבל איך זה מתבצע? בואו נגלה.
1. בניית הגרף מהטקסט – בהינתן הטקסט, החוקרים מחלצים ממנו שלישיות של נושא-פועל-נשוא (למשל רעידת אדמה מגיעה מרעידה ואדמה). מהשלישיות הם מפעלים אלגוריתם אשכולות Extract-Clustering-Coreference. האלגוריתם מקבץ ביחד קודקודים הקשורים כולם לאותו קודקוד, למשל רעידת אדימה-מגיעה-רעידה ואדמה | רעידה, אדמה-שהמשמעות שלהם-אדמה ורועדת. לכן זה יהיה אשכול שממנו ניתן להסיק שרעידת אדמה -> אדמה, רועדת.
2. הגרף מקודד באמצעות Graph Encoder המבצע שיכון של כל קודקוד על ידי שימוש בשכנים שלו (כלומר משתמשים במטריצת השכינויות של הגרף).
3. הטקסט מקודד באמצעות Encoder רגיל
4. תמונות (אם קיימות) מקודדות באמצעות Vision Encoder.
5. משתמשים ב-cross attention כדי לבצע תיקון לקידודים כך שהשיכון יהיה באותו מרחב קידוד.
6. מאחדים את כלל הקידודים ביחד ומשתמשים ב-Transformer Decoder בשביל לייצר את התשובה
לצורך אימון הם אימנו על הדאטהסטים:
- text-only GSM8K
- Multimodal ScienceQA
התוצאות מראות שיפור מול המתחרהCoT שמתמשים במודל הזהה בגודל למודל שלהם.
30.08.23: OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
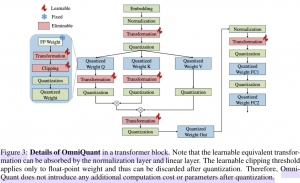
קוונטיזציה (quantization) של מודלי שפה הפך להיות נושא חם לאחרונה. מודלי שפה הפכו להיות ענקיים ומכילים עשרות מיליארדי פרמטרים וגודלם נמדד בגיגבייטים. כדי לאפשר הפעלה מהירה של מודלי שפה (וגם חסכון במקום האכסון). היום ב- #shorthebrewpapereviews סוקרים גישה חדשה לקוונטיזציה של מודלי שפה המשלבת טכניקות שהוצעו בכמה עבודות קודמות וגם מציעה כמה חידושים. נתחיל מרענן מהי מטרת הקוונטיזציה? המטרה היא ״לדחוס״ את מודל השפה באופן שהפגיעה בביצועים (inference) תהיה מינימלית (בד״כ בהינתן תקציב דחיסה נתון כלומר מקדם הדחיסה). קודם כל המחברים מייצגים את בעיית הקוונטיזציה בבעיית מזעור(minimization) של ההפרש בין התוצאת החישוב של המודל ב-precision מלא והתוצאה של המודל המקוונטט (על סט הולידציה) עבור כל בלוק טרנספורמר (יחידה בסיסית של כל llms היום). עכשיו נשאלת השאלה מה הפרמטרים של בעיית מזעור זו? המאמר מציע לשלב שתי טרנספורמציות נלמדות (פר בלוק הטרנספורמר): הראשונה היא פעולת קוונטיזציה עצמה של משקלי המודל (מבוצעת באמצעות טרנספורמציית min-max עם שני פרמטרים של scaling נלמדים). הפעולה השניה היא טרנספורמציה לינארית של פלטי הביניים של המודל עם פרמטרים נלמדים. למשל הפלט של בלוק טרנספורמר מסוים מוכפל במטריצה ומוזז (פרמטרים נלמדים) לפני שהוא נכנס לבלוק הטרנספורמר הבא. נציין כי יש פרמטרים שונים לטרנספורמציה לינארית בכניסה למנגנון תשומת הלב. שילוב קווינטוט עם טרנספורמציה של הפלט (משום מה נקרא activation במאמר שזה קצת מבלבל) מביא לדחיסה יעילה של מודל שפה עם פגיעה מינורית בביצועים.

31.08.23: LM-INFINITE: SIMPLE ON-THE-FLY LENGTH GENERALIZATION FOR LARGE LANGUAGE MODELS
https://arxiv.org/abs/2308.16137.pdf
אורך ההקשר (context length) של מודלי שפה או במילים אחרות הגודל המקסימלי של הטקסט המודל שפה יכול ״לזכור הפך להיות נושא מאוד פופולרי בקהילת ה-NLP עקב חשיבותו הרבה ליישומים רבים. יצאו עשרות (אם לא מאות מאמרים) המנסים להגדיל אותו והיום ב-#shorthebrewpapereviews אנו נסקור מאמר המציע גישה חדשה חהארכת אורך ההקשר. קודם כל המחברים מזהים (וסוג של מוכיחים) למה מודלי שפה שאומנו עם קלט קצר יחסית ועם קידוד תלי מיקום יחסיים (RoPE) מתקשים עם קלט יותר ארוך באינפרנס. אז לפי המאמר יש 3 סיבות עיקריות.
- או ש- rope מתעלם מהטוקנים הרחוקים (מקדמי attention לפני softmax שווים ל-0 ) או שהם מקבלים ערכים גבוהים מאוד
- ככל שמאריכים את אורך ההקשר האנטרופיה של מקדמי ה-attention שואפת ל-log(N) כאשר N זה מספר הטוקנים כלומר המודל מתחשב בכל הטוקנים באותה מידה
- המודל מקודד באופן לא מפורש את המיקום האבסולוטי של הטוקנים בסדרה (המאמר מסביר את זה בכך ש״הסיגנל מהטוקנים ההתחלתיים חזק יותר מהאלה שבסוף)
כדי להתמודד עם 3 סוגיות האלה המאמר מציע גישה די פשוטה לקידוד תלוי מיקום:
- עבור טוקן נתון הם מקודדים (עם RoPE או משהו דומה) מספר טוקנים מסוים (נגיד שווה לאורך ההקשר ״הסטנדרטי״ של מודל שפה) המופיעים בהתחלת הסדרה (global branch)
- כל טוקן גם מקודד (attend) את מיקום טוקנים הנמצאים במחרחק מסוים ממנו (local branch)
לפי המאמר כך הטוקנים שבהתחלה בעיקר מקודדים בעיקר את המיקום האבסולוטי של הטוקן, אלה שבסוף את המיקום היחסי שלו ואלו שבאמצע מכילים פחות מידע מיקומי ( לא הבנתי את למה בעצם).
01.09.23: ORES: Open-vocabulary Responsible Visual Synthesis
https://arxiv.org/abs/2308.13785.pdf

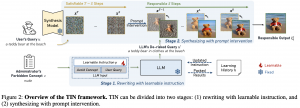
כיום מודלים לגנרוט תמונות לפי תיאור טקסטואלי מסוגלים ליצור תמונות באיכות מדהימה שממש תואמות את התיאור. בנוסף נהיה קשה מאוד עד בלתי אפשרי להבחין האם תמונה הינה טבעית״ נוצרה על ידי מודל גנרטיבי שפותח פתח ליצירת פייקים באיכות גבוהה מאוד שעלולים לגרום לנזק רב. היום ב-#shorthebrewpapereviews סוקרים מאמר שפיתח שיטה פשוטה למניעת יצירת פייקים מסוכנים. השיטה המוצעת מאוד פשוטה אינטואיטיבית. נניח שיש לנו פרומפט שבאמצעותו המשתמש רוצה ליצור תמונה. בנוסף יש לנו גם יש לנו גם סט של קונספטים (מושגים) אסורים (כמו ערום, דם וכאלו). בשלב הראשון הופכים את הפרופמט לבטוח (בהתאם לקונספטים האסורים) עם מודל שפה מאומן. המחברים בחרו דאטהסט קטן המכיל שלישיות של (פרומפט, מושג אסור, פרומפט בטוח) ובהתבסס עליו מצאו את הפרומפט (אחד) למודל שפה שבאמצעותו ניתן להפוך הנחיה נתונה יחד עם הקונספט האסור להנחיה בטוחה על ידי הרצה של הדאטהסט הזה על מודל שפה מספר אפוקים. לאחר מכן מכניסים את הפרומפט בטוח למודל דיפוזיה מאומן. כדי לגנרט תמונה דומה לפרומפט המקורי ב- S הצעדים ההתחלתיים של מודל הדיפוזיה (מתחילים מרעש טהור) וב- T – S הצעדים האחרונים מבצעים עם הפרומפט הבטוח.