תוצאות סקר קהילת MDLI 2019 – הדו"ח המלא

השנה, בדיוק כמו שנה שעברה, קיימנו סקר מקיף אודות מגוון רחב של נושאים בקרב חברי קהילת MDLI. הסקר בא לבחון אלמנטים הנוגעים בתנאי העסקה, אתגרים יומיים, כלים נפוצים שבשימוש ועוד עבור אלו שעוסקים במקצעות הדאטה. בסקר הנוכחי השיבו 569 איש בסה"כ (לעומת 225 בשנה שעברה) אשר מייצגים בצורה נרחבת את כל הקשת הישראלית בתחום. המידע נאסף עד חודש מרץ 2019 ועדכני לנקודת זמן זו. בדו"ח הבא נציג את התוצאות הישירות שעלו מתוך הסקר ולצד זאת מספר ניתוחי עומק שביצע עומרי גולדשיין על הנתונים וזאת כדי לחשוף קשרים ורבדים עמוקים יותר בין הנתונים. השאלון נבנה משני חלקים עיקריים: חלק ראשון אישי ותעסוקתי ולצידו, חלק שני מקצועי וטכני יותר. בסקירה הזו, נציג לכם את התובנות העיקריות שעלו מהסקר ואת המסקנות לכל מי שבתעשייה זו.
אחד האלמנטים העיקריים בדו"ח הוא נושא השכר הממוצע בתחום בהתאם לניסיון בתעשייה והשכלה אקדמית. השנה הסקר כלל תשובות של כ-402 איש העוסקים בתחום במשרה מלאה – מה שמעניק תמונת מצב טובה על התחום. עומרי פיתח שני מודלים שיסייעו לכם לחזות מה אמור להיות השכר הממוצע שלכם בהם תוכלו לעשות שימוש. אחד מפרויקטי ההמשך של הסקר הוא הכנת מחשבון שכר בו יהיה ניתן להזין פרטים אודתיכם ולאחר מכן לקבל את השכר הממוצע עבור אנשים עם פרופיל זהה. מתוך הבנה כי על אף שמדובר על מספר גדול ביחס לסקרי שכר אחרים, הנתונים עדיין יכולים להיות לא מדויקים במקרים מסוימים ולכן נרצה להוסיף דוגמאות נוספות. מחשבון שכר זה יעלה בשבועות הקרובים ויאפשר גם מתן פידבק על התוצאות לשם שמירתו עדכני לאורך זמן.
דמוגרפיה
74.1% מ-569 המשיבים הם גברים, ואילו 25.3% הן נשים. זוהי עלייה משמעותית באחוז הנשים משנה שעברה, שככל הנראה נובעת ממאמץ נוסף להגיע לנשים רבות יותר על מנת לקבל תובנות גם על אוכלוסיה זו ולאו דווקא מעלייה באחוז הנשים בתחום. הגיל הממוצע היה 32.7 שנים, כאשר 50% מהמשיבים היו בגילאי 29 עד 35:

לא היו הבדלים בהתפלגות הגילאים בין גברים לנשים, אולם חיתוכים אחרים יכולים ללמד מעט על הדמוגרפיה של המשיבים. למשל, בתל אביב הגיל החציוני של המשיבים היה 30, בעוד שבמחוז המרכז 33:

לתל אביב היה את הייצוג הרב ביותר הן כעיר המגורים והן כעיר אליה מגיעים כדי לעבוד. תל אביב מושכת אליה כמעט מחצית מאלו שגרים במחוז המרכז, כרבע מהחיפאים, שליש מהירושלמים וקצת פחות ממחצית המתגוררים במחוז הדרום. למעשה זוהי העיר היחידה שמשמשת כמקום עבודה יותר משהיא משמשת כעיר מגורים. אין לי נתונים משנים אחרות, אבל לתחשותי מדובר בשינוי של השנים האחרונות – אם בעבר המונח "מרכז הייטק" התקשר (לפחות אצלי) למרכזי פיתוח ברחובות, פתח-תקווה, הוד השרון וכו', כיום נראה שלדומיננטיות התל-אביבית אין תחרות (אם תבקרו בלובי של אחד מהמגדלים החדשים לאורך נתיבי איילון סביר שתגלו שהם מאוכלסים במספר גדול של חברות סטארט-אפ והייטקיסטים שמאוד דומים זה לזה פיזית ואופנתית):
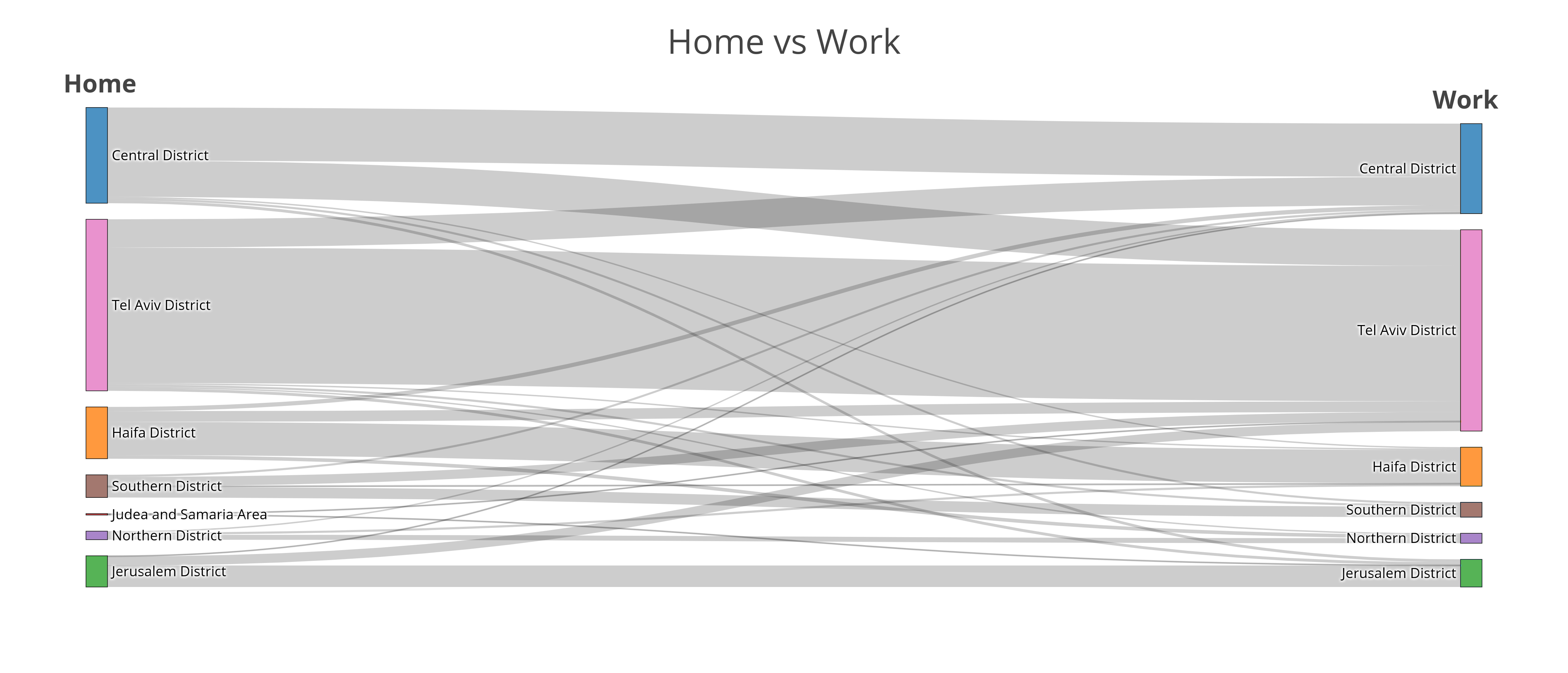
לסקר ענו עובדים ועובדות בסוגי חברות שונות, מתאגידים ועד לצה"ל. כצפוי, המשיבים הצעירים ביותר עובדים בצבא הקבע. העובדים המבוגרים ביותר, בממוצע, נמצאים במגזר הממשלתי, שם הגיל החציוני הוא 36, ואילו הגיל החציוני בסטארט-אפים ובתאגידים הוא 32:

התפקידים הנפוצים ביותר היו דאטה סיינטיסט\ית, חוקר\ת או מדען\ית, מהנדס\ת דיפ לרנינג מהנדס\ת מאשין לרנינג, מפתח\ת תוכנה, מפתח\ת אלגוריתמים, אנליסט\ית ו-CTO . תוצאה לא מקרית בהתחשב בכך שהסקר מלכתחילה כוון למדעני נתונים, וכמובן לא מעידה על תעשיית ההיי-טק בכללותה. התארים הנפוצים ביותר היו מדעי המחשב (כאן נכנסו גם הנדסת חשמל, הנדסת תוכנה וביו-אינפורמטיקה), תארים בהנדסה ומדעים מדויקים (מתמטיקה, פיזיקה, סטטיסטיקה, הנדסות שונות שאינן חשמל או תוכנה), מדעי הטבע (תחת הקטגוריה הזו נכנסו כימיה, ביולוגיה ומדעי המוח) וכלכלה. מעניין לראות את הקשר בין התארים השונים לתפקידים:

בעוד שאת בוגרי מדעי המחשב ניתן למצוא בכל סוגי התפקידים, רוב בוגרי המדעים המדויקים וההנדסות מוגדרים כדאטה סיינטיסטים, וכן רוב בוגרי מדעי הטבע. באופן לא מפתיע מהנדסי התוכנה הם בוגרי מדעי המחשב באופן כמעט בלעדי. דאטה אנליסטים הם בעיקר בוגרי המדעים המדויקים, ורוב הנותרים והנותרות מתחלקים\ות בין בוגרי מדעי הטבע וכלכלה.
אם נמפה את התפקיד, רמת ההשכלה ותחום הלימודים למפה דו-מימדית באמצעות MCA (האחות הקטגוריאלית של PCA) נוכל לראות קשרים מעניינים בין המשתנים:
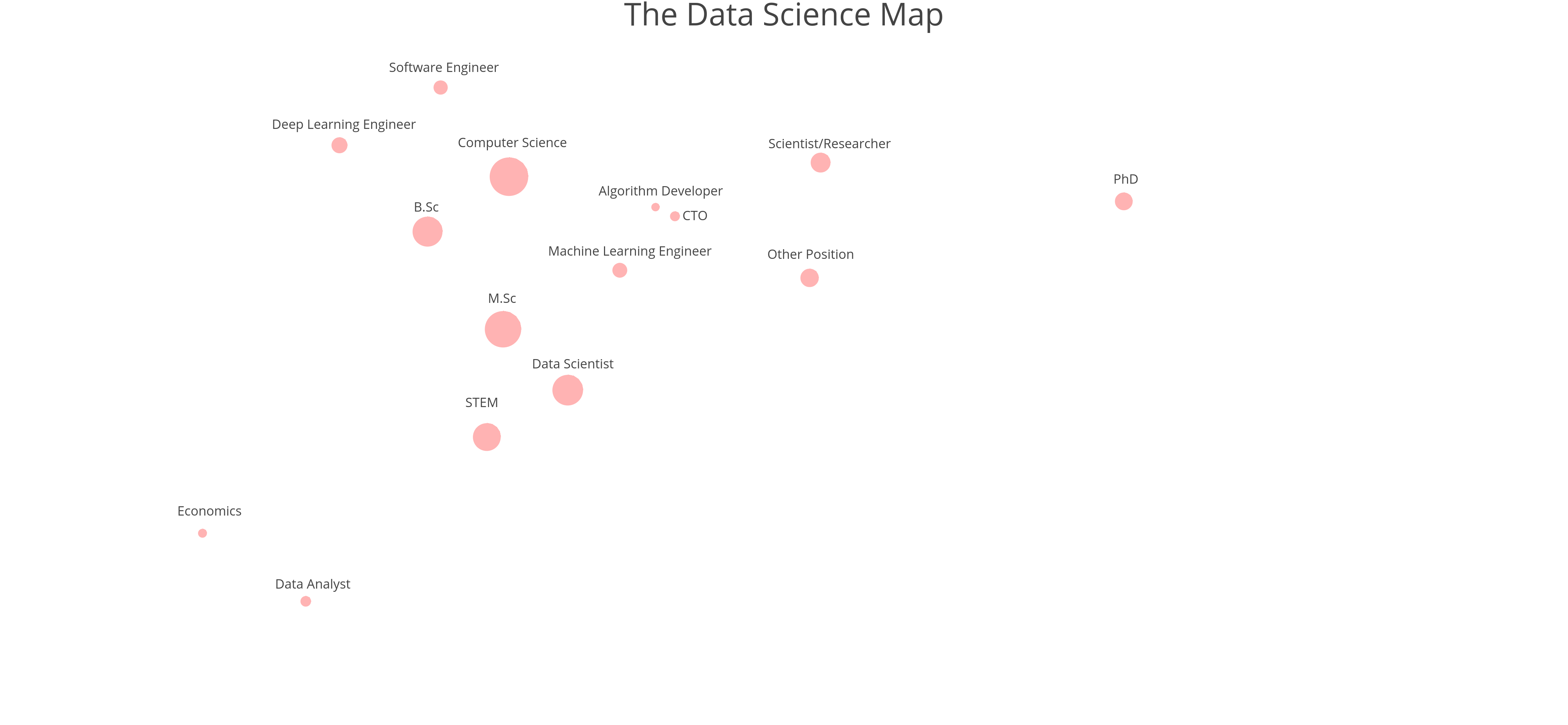
ניתן לראות מספר מקבצים – בצד שמאל למטה, את הקשר בין בוגרי כלכלה לתפקיד דאטה אנליסט (על אף שלא מעט בוגרי כלכלה הם דאטה סיינטיסטים). במרכז, הקשר בין בוגרי תואר שני בתחמי ה-STEM והגדרת התפקיד "דאטה סיינטיסט". בצד שמאל בולט האגף ההנדסי יותר, איפה שנמצאים בוגרי תואר ראשון במדעי המחשב שמועסקים כמהנדסי תוכנה ומהנדסי דיפ לרנינג. ואילו בצד ימין למעלה, במקבץ מעט פחות מובהק, הדוקטורים שמועסקים כחוקרים. במרכז מופיעים המאפיינים הפחות מובהקים: CTO, מפתחי אלגוריתמים ומהנדסי מאשין לרנינג שנמצאים במרחק דומה לרמות השכלה ותחומי לימודים שונים – כלומר מדובר באוכלוסיה מעט מגוונת יותר מבחינה מקצועית.
היכן מחפשים עבודה?
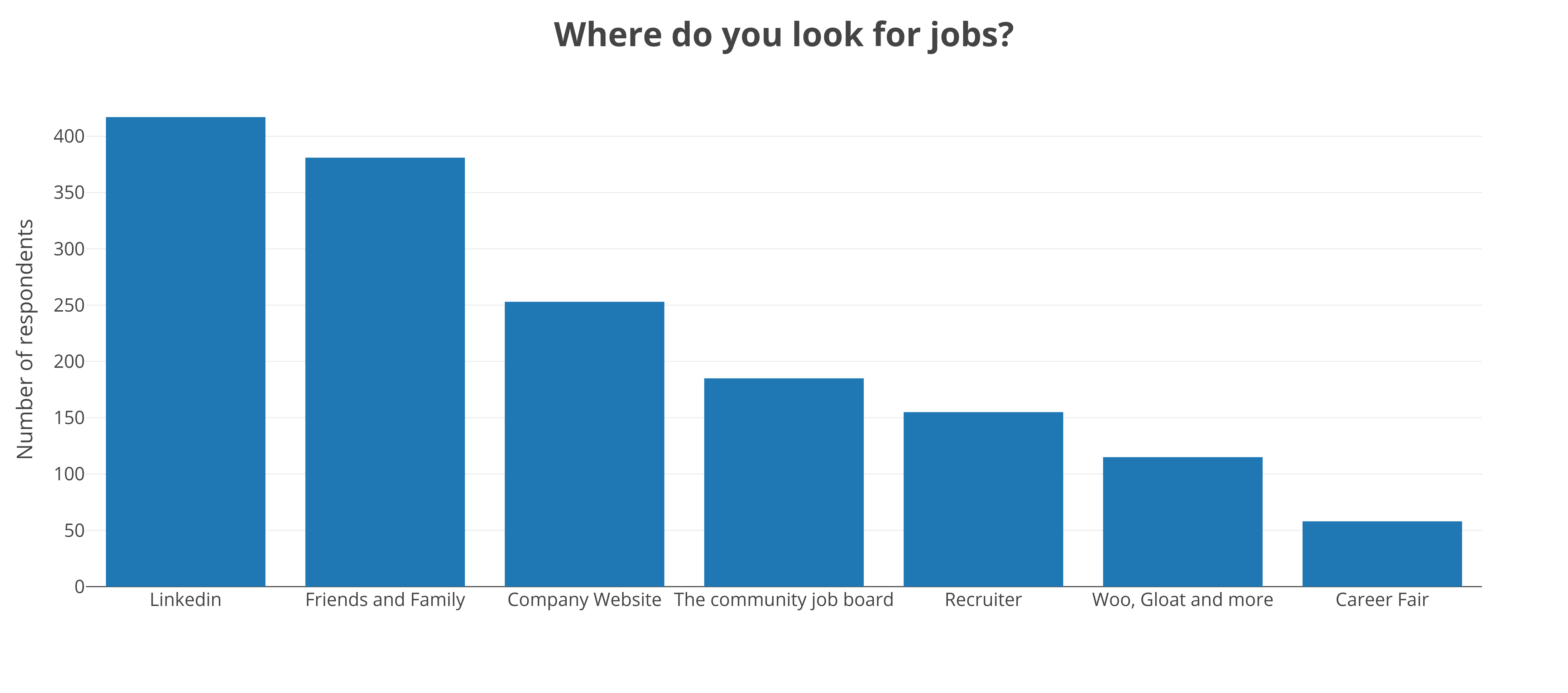
שוק הגיוס השתנה בשנים האחרונות, והשינוי הזה ניכר גם בתוצאות הסקר. חברות כמו woo ו-gloat שינו את האופן בו מחפשים עבודה, אם כי עדיין נראה שמרבית המשיבים לא משתמשים בשירותיהן. יחד עם זאת הרשת החברתית לינקדאין היא עדיין האתר הפופולארי ביותר לחיפושי עבודה עם יותר מ-400 משיבים שציינו אותה (זו הייתה שאלת בחירה מרובה כך שהסכום כמובן גדול ממספר המשיבים). השיטה הפופולארית הבאה היא חיפוש באמצעות חברים ומשפחה. במקום הרביעי הגיע לוח המשרות של הקהילה. פחות ממחצית מהמשיבים משתמשים בשירותיהם של מגייסים.
שכר
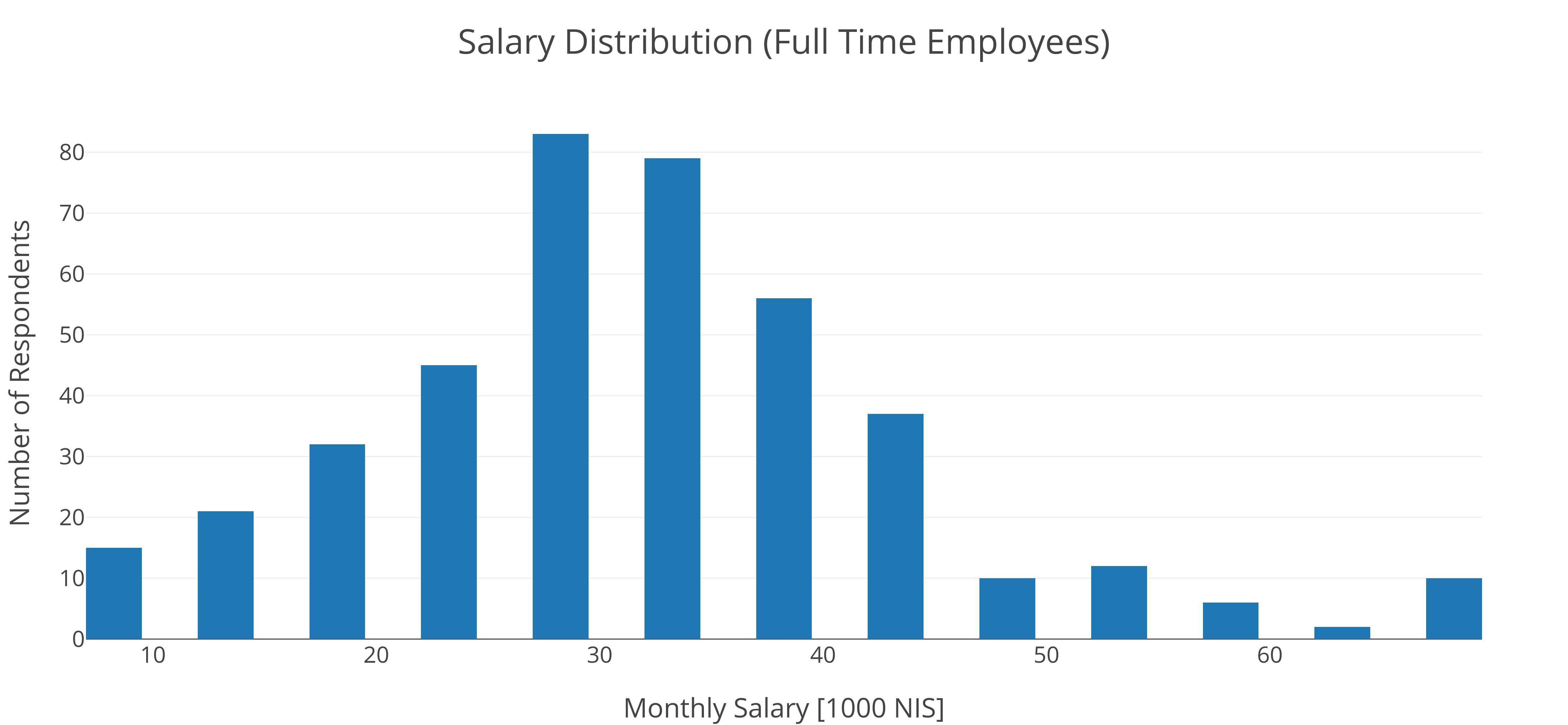
השכר הממוצע לעובדים במשרה מלאה במדגם היה 31,000 שקלים בחודש, עלייה של 2,000 שקלים מהשנה הקודמת. 50% מהמשיבים היו בטווח (הרחב) של בין 22.5 ל-37.5 אלף ש"ח, מה שמראה על שונות מאוד גבוהה בין המשיבים:
פער השכר הממוצע בין גברים לנשים עמד בסקר השנה על 2,600 שקלים שהם כ-8 אחוזים, דומה מאוד לשנה שעברה (השכר הממוצע עבור גברים היה 31.5 אלף ש"ח לחודש, לעומת 29 אלף שקלים לנשים).
את השכר הגבוה ביותר מרוויחים מי שהגדירו את תפקידם כחוקרים\ות או מדענים\ות, עם שכר ממוצע של כ-36 אלף שקלים בחודש, ומעט אחריהם CTO ומהנדסי\ות מאשין לרנינג עם שכר של כ-35 אלף שקלים לחודש. אנליסטים\יות, לעומת זאת, השתכרו כ-19 אלף שקלים בחודש בממוצע.
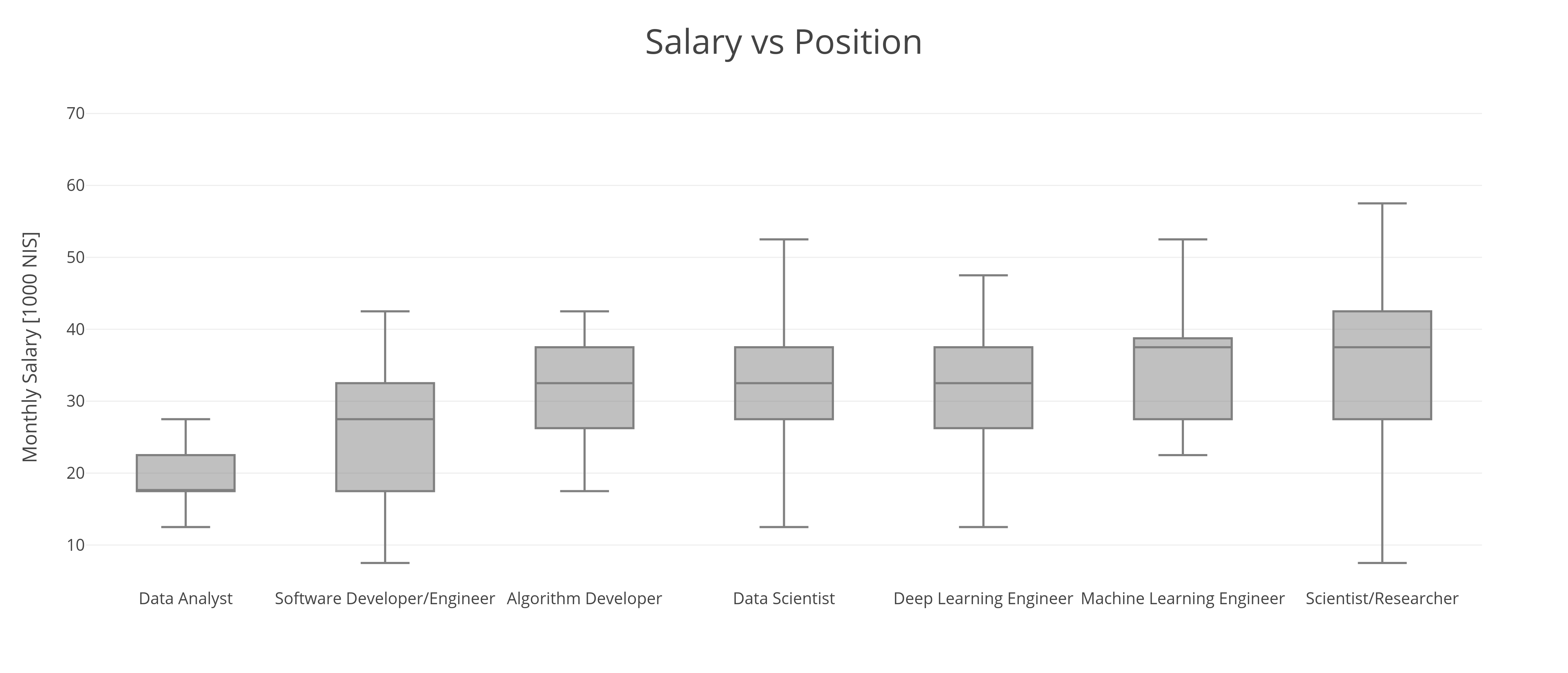
בעוד שנשים היוו כ-23% אחוז מהמדגם, 45% מהאנליסטים והאנליסטיות הן נשים, מה שמסביר לפחות באופן חלקי את פערי השכר, אך לא את כולם. דאטה סיינטיסט גבר הרוויח 31 אלף שקלים בממוצע, 3,000 יותר מאישה באותו תפקיד. פער דומה מאוד היה בין חוקרים (37 אלף שקלים בחודש) לחוקרות (34).
פקטור שמשפיע מאוד על השכר הוא ההשכלה. בדומה מאוד לשנה שעברה, גם השנה רמת ההשכלה הנפוצה ביותר היא תואר שני (51% מהנשאלים), לאחר מכן תואר ראשון (33%) ודוקטורט (12%). השכר עולה באופן ברור עם ההשכלה, כאשר בעלי תואר ראשון במדגם הרוויחו בממוצע כ-27 אלף שקלים, בעלי תואר שני 31 אלף, ואילו בעלי דוקטורט הרוויחו בממוצע לא פחות מ-38 אלף שקלים. פערי השכר המגדריים בחיתוך לפי השכלה מעניינים במיוחד: בעוד שהשכר הממוצע עבור בעלי תואר שני היה זהה עבור גברים ונשים, פער השכר בקרב בעלי דוקטורט היה אסטרונומי – 41 אלף שקלים לגברים לעומת 27 אלף שקלים לנשים. חלק מהפער נובע מכך שמקרב הנשים בעלות הדוקטורט, בכמחצית מהמקרים הדוקטורט הוא בביולוגיה, כימיה או מדעי המוח, והשאר במדעי המחשב או הנדסה. אצל הגברים, לעומת זאת בכ-82% מהמקרים מדובר בדוקטורט במדעי המחשב או הנדסה:

מה שכמובן מוביל אותנו לשלב הבא, והוא פילוח השכר בהתאם לתחום הלימודים. התואר הנפוץ ביותר, בפער עצום, היה מדעי המחשב, עם יותר מ-56% מהמשיבים. עוד כ-28% למדו הנדסה, פיזיקה, מתמטיקה או סטטיסטיקה, והשאר התחלקו בין בוגרי מדעי הטבע, כלכלה ומדעי החברה שאינם כלכלה. מדעני המחשב גם הרוויחו את השכר הגבוה ביותר, כ-33 אלף שקלים בחודש. בוגרי ההנדסה אחריהם, מקדימים במעט את בוגרי מדעי הטבע עם שכר ממוצע של כ-28 אלף שקלים. שווה לציין שכמעט כל בוגרי מדעי הטבע במדגם, בשונה מאוד מבוגרי ההנדסה ומדעי המחשב, הם בעלי ובעלות דוקטורט. בוגרי תואר בכלכלה הם הבאים בתור, עם שכר ממוצע של כ-25 אלף שקלים בחודש.

גורם נוסף המשפיע על השכר הוא כמובן הגיל. באופן צפוי למדי, השכר עולה עם הגיל וכן עם הניסיון. האפקט קיים הן אצל גברים והן אצל נשים, אולם פערי השכר גדולים הרבה יותר בגילאים המבוגרים יותר במדגם.

אחת הסיבות לקפיצה האסטרונומית בשכר, מעבר לעלייה בניסיון ובהשכלה, היא העובדה הפשוטה שכ-14 מהמשיבים עובדים בצבא הקבע, מה שמטה את השכר משמעותית כלפי מטה עבור המשיבים בשנות ה-20 המוקדמות שלהם. מעבר לכך, ואולי כצפוי, השכר גבוה יותר בתאגידים וחברות סטארט אפ – מה שרבים יחשיבו פשוט כ'תעשיית ההיי-טק' – לעומת המגזר הממשלתי, הפיננסי, האוניברסיטאות וכו'. שימו לב כי הזנב בתאגידים ארוך יותר – רמות השכר הגבוהות ביותר נמצאות בחברות ענק כמו גוגל, אמזון, פייסבוק ודומותיהן:

אם נסתכל על אופי החברה ברזולוציה גבוהה יותר, לפי מספר העובדים, ניתן להבחין ככל הנראה בהשפעה של ענקיות הטכנולוגיה דוגמת אמאזון, פייסבוק, גוגל וכו' (זוהי ספקולציה, המשיבים לא ציינו את מקום עבודתם). בעוד שהשכר קופץ למעלה ולמטה ככל שהחברה גדלה ללא מגמה ברורה, עבור חברות עם יותר מ-10 אלף עובדים, 25% מהמשיבים מרוויחים יותר מ-46 אלף שקלים בחודש:

כפי ששמנו לב, כשמציירים את התפלגות השכר כפונקציה של משתנה בודד, מתקבלת לא פעם תמונה מטעה. ראינו שהשכר של בוגרי ובוגרות מדעי הטבע גבוה כמו השכר של בוגרי ובוגרות מקצועות ההנדסה, אולם בוגרי מדעי הטבע בדרך כלל מצוידים בתארים גבוהים יותר. ראינו שהשכר של המשיבים הצעירים מוטה כלפי מטה מכיוון שרבים מהם משרתים בקבע. קשה לנטרל את כל האינטראקציות השונות בין המשתנים, ואפילו אם נעשה כן, עוד יותר קשה להסיק מכך סיבתיות. אנחנו ננסה לעשות משהו צנוע בהרבה, והוא לבנות מודל פשוט (עץ החלטה) שינסה לנבא את השכר של משיב או משיבה בסקר בהתאם לתשובותיהם על השאלות.
כמה הערות חשובות מאוד לפני המודל:
- השילוב של מעט דאטה יחד עם שונות רבה לא מאפשרים רמה מאוד גבוהה של דיוק. 402 משיבים שעובדים במשרה מלאה הם המון לסקר שכר, אבל מעט מאוד בשביל מודל סטטיסטי.
- המודל יכול בקלות לשגות בכ-4000 ש"ח לכאן או לכאן, וברמות השכר הגבוהות ביותר גם בהרבה יותר מכך. בסה"כ, השונות המוסברת על ידי המודל עבור דאטה חדש (אם כי עדיין כזה שנלקח מהמדגם) היא כ-30%, מה שבהחלט משאיר מקום להרבה שגיאות. המטרה היא לתת מבט הוליסטי על האופן בו המשתנים השונים משפיעים על השכר וכיצד נראית האינטראקציה ביניהם, לא לתת תחזית שכר מדויקת.
- המודל לא מתאר סיבתיות, ויותר מכך, הוא עשוי לזהות קורלציות שמקורן בגורם חבוי כלשהו. כך, למשל, המודל יכול לזהות "גיל צעיר" כמנבא שכר נמוך, רק מכיוון שאין לו גישה לסוג החברה (מה שהיה מאפשר לו לזהות את הכלל שהשירות בצבא הקבע הוא זה שקורלטיבי לשכר נמוך, ולאו דווקא הגיל עצמו).
- מובן מאליו שהמודל מתאר מצב מצוי ולא מצב רצוי. כך למשל, בנקודות מסוימות המודל שואל את המשיב\ה, בניסיון לנבא את שכרו או שכרה – האם את\ה אישה? בכל המקרים שבו השאלה הזו נשאלת, התוצאה היא שהמודל מנבא שכר גבוה יותר לגברים. נושא פערי השכר בהייטק בפרט ובמשק בכלל הוא מורכב, אבל אם יש איזשהו שימוש ראוי לנתון כזה, הרי שהוא לעודד נשים (וגברים) להתמקח על שכר.
- על מנת להדגים את רגישות עץ ההחלטה, אני מציע שני מודלים. המודלים דומים, אולם מעט שונים הן במשתנים שהותר להם להשתמש בהם, והן בכללי ההחלטה (לדוגמא, מה המספר המינימלי של משיבים שיכולים להיות בעלה).
- על מנת לשמור הן על כושר ההכללה של המודל, והן על האנונימיות של המשיבים, בכל מקרה בכל עלה יהיו תמיד לא פחות מ-20 משיבים.
מודל מספר 1:

מודל מספר 2:

כמה מסקנות מהמודל:
- שנות הניסיון, ע"פ המודל, הן הגורם החשוב ביותר. שווה לציין שהמספר 6 אינו מספר קסם, אלא נובע מהאופן בו נשאלה השאלה (טווחי הניסיון חולקו ל-2-3, 3-5, 6-10 וכו').
- המשתכרים הגבוהים ביותר ע"פ מודל 1 הם בעלי דוקטורט שיש להם יותר מ-6 שנות ניסיון, ואילו ע"פ מודל 2 אלו העובדים עבור חברות ענק (מעל 10 אלף עובדים), גם כן עם יותר מ-6 ניסיון. בשני המקרים מדובר בשכר ממוצע של 45,000 שקלים. שווה לציין שמדובר פחות או יותר באותם אנשים. כמובן שאין לי גישה למקומות העבודה שלהם, אבל יתכן שמדובר בענקיות ההיי-טק – גוגל, אמאזון, פייסבוק, אפל וכיו"ב, שיש להן גם את הפריווילגיה להעסיק את המנוסים והמשכילים.
- בכל מקום בו נשאלה השאלה "האם למדת מדעי המחשב?" התשובה "כן" הוליכה לשכר גבוה יותר.
- כאמור, בכל מקום בו נשאלה השאלה "האם את\ה אישה?", התשובה "כן" הוליכה לשכר נמוך יותר. כך למשל, עבור בעלות 6 שנות ניסיון שאין להן דוקטורט, שכר הנשים היה נמוך בכ5,000 ש"ח משכר הגברים. חלק מהפער יכול להיות מוסבר על ידי ריבוי בוגרי המחשב בקרב הגברים, אולם גם בקרב הנשים הרוב המוחלט בקבוצה הזו היו בעלות תואר במדעי המחשב או הנדסה (אם כי מעט פחות מאצל הגברים). פערים דומים נמצאו כאמור גם עבור מעוטי הניסיון. מעניין לציין שבקבוצות בהן רמת השכר קרובה יותר לממוצע, פערי השכר המגדריים קטנים יותר. מכל מקום ניתוח מלא של פערי השכר המגדריים הוא הרבה מעבר לגבולות הפוסט.
מקצועי
חלק בלתי נפרד מעבודתו של מדען נתונים הוא הדאטה איתו הוא עובד והדרכים בהן הוא משיג אותו. כפועל יוצא מכך, הבאנו חלק משמעותי בסקר לשאלות סביב הדאטה עמו חברי הקהילה עובדים. 62.7% מהמשיבים ציינו כי הם אוספים את הדאטה באופן עצמאי ללא כל שימוש במקורות דאטה אחרים. לעומתם, 26.8% משיגים את הדאטה שלהם מאגריגטורים של דאטה, 17.8% משיגים את הדאטה באמצעות חיפוש בגוגל בעוד ש15.4% משיגים את הדאטה דרך אונבריסטאות או אירגונים ללא מטרות רווח אחרים. כל השאר משיגים את המידע או דרך GitHub או אתרים ממשלתיים.
כאשר צללנו פנימה לגבי סוג הדאטה בו נעשה שימוש קיבלנו תוצאות מעניינות למדי: 46.3% מהמשיבים ציינו כי הם עובדים על מידע רלציוני, ומיד אחריהם עם 43.7% מהתוצאות ציינו המשיבים כי הם עובדים על מידע ויזואלי (תמונות). במקום השלישי הגיע דאטה טקסטואלי עם 39.3%, לאחריו הגיע דאטה מסנסורים עם 27.3% מסך הקולות. את תחתית הרשימה סגרו דאטה מסוג "וידאו" עם 19.8% ודאטה מסוג "אודיו" עם 8.8% מהקולות.

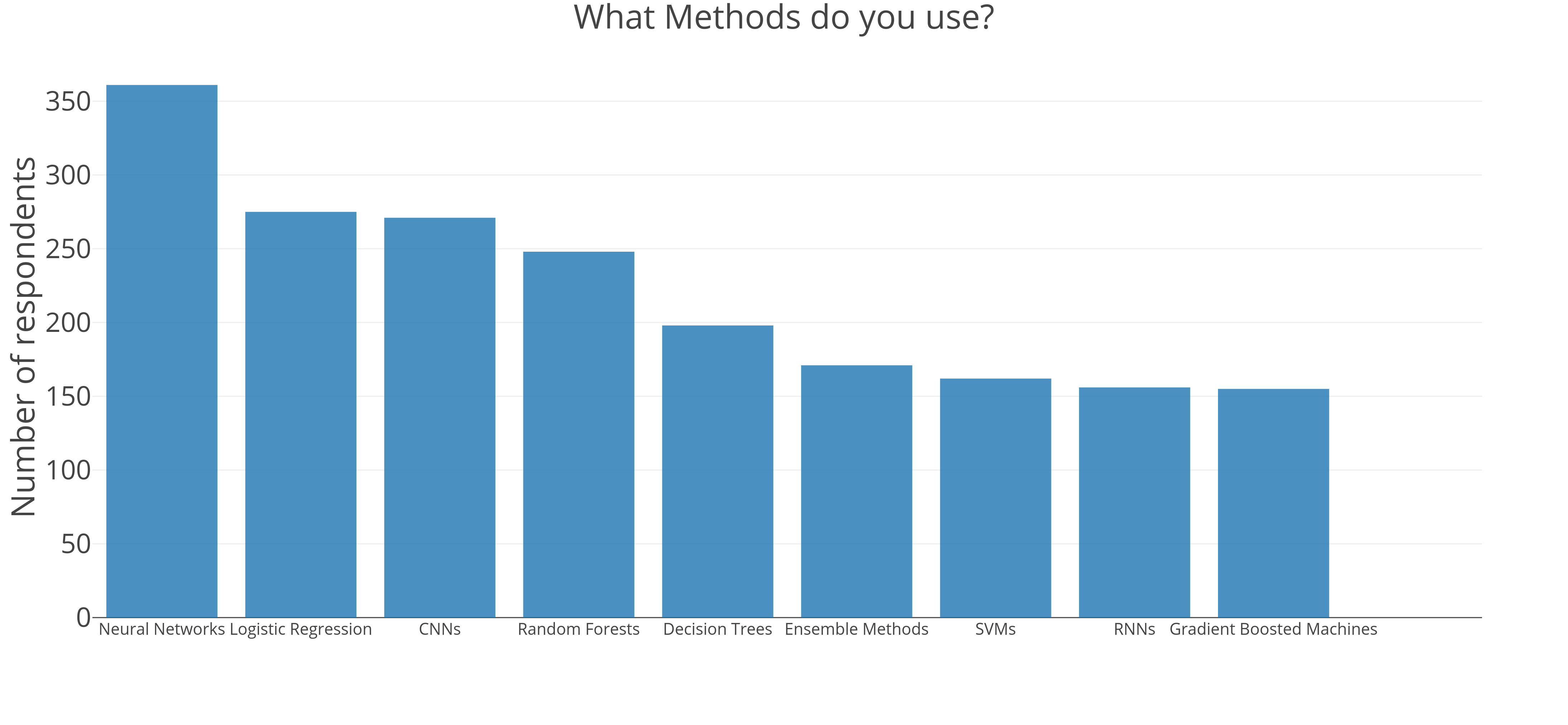
לאחר שהבנו איזה סוג דאטה פופלארי והיכן הוא נאסף הגיע הזמן להתעמק ולהבין מה חברי הקהילה עושים עם הדאטה. בשאלה הבאה רצינו לדעת באילו מתודלוגיות הם משתמשים ומה הן הטכניקות העיקריות בשגרת העבודה שלהם. גם במקרה זה התוצאות היו מאוד מגוונות כאשר לא מעט ציינו כי הם עובדים עם מספר רב של טכניקות. את ראש הטבלה קטפו רשתות נוריונים עם 67.9% מסך המצביעים, מיד אחריהן, עם 51% מהמצביעים עבור כל קטגוריה, הגיעו CNN ו-Logistic Regression. במקום הרביעי, עם 45.8% הגיע Random Forests ומיד אחריו עם 36.6% הגיע Decision Trees. לקראת הסוף, הגיע Ensemble Methods עם 31.7% מהקולות, SVM עם 30.1% ו-RNN עם 29.5%. בהמשך הרשימה הגיעו GANs ל15.9% מכלל ההצבעות.
בשלב זה נשאלה השאלה, באילו ספריות משתמשים משיבי הסקר כדי לבצע את כל אותן טכניקות שהוזכרו בפסקה הקודמת. לראש הרשימה הגיעה TensorFlow עם 50.6% מהקולות, במקום השני Keras עם 46.6% מהקולות ובמקום השלישי עם 40.5% הגיעה PyTorch. למקום הרביעי הגיעה Gensim עם 7.6% בעוד שאת המקום החמישי קטפה Matlab עם 7.3%.
לסיום, את הסקר חתמנו עם השאלה הבאה: מה הם החסמים העיקריים שניצבים בפניכם בעבודה? באופן לא מפתיע, בדומה לשנה שעברה, הבעיה העיקרית, עם 60.7%, הייתה דאטה לא טוב (Dirty Data) אשר פוגעת בעבודה הרציפה. מיד אחריה, הבעיה השנייה עם 35.1% מכלל המשיבים, הייתה חוסר גישה לדאטה או הזמינות שלו. כפי שהבנתם, עיקר הבעיות בתחום כיום הן סביב עולמות הדאטה – הן סביב ההשגה שלו והן סביב האיכות שלו. במקום השלישי עם 29.3% מהקולות, הגיע המחסור בטאלנט בתחום. המחסור במדעני נתונים ידוע ומוכר והיעדר אנשים איכותיים מקשה על חברות להמשיך ולהתקדם בפיתוחים שלהן.

הבעיות הבאות בתור שהגיעו לדירוגים גבוהים נוגעות דווקא לממשקים אחרים בעבודה שהם לא בהכרח טכניים. 24.7% מהמשיבים ציינו כי הקושי הגדול שלהם נובע מהיעדר שאלה ברורה לענות עליה, בעוד ש17.6% ציינו כי הבעיה היא היעדר של מומחה תוכן שאפשר להתייעץ איתו. את הרשימה סגרה אחת הבעיות הגדולות והמוכרות: הצורך להסביר את עבודת מדען הנתונים לאחרים עם 15.6%.
סיכום
נראה כי מרבית המגמות משנה שעברה נשמרו בצורה יחסית עקבית ולא נראה שיש שוני מהותי. השכר בתחום ממשיך לעלות בעקבות הביקוש הרב שיש לאנשים בתחום, ונראה כי הוא ימשיך לטפס גם בעתיד. עם זאת, ועל אף חסמי הכניסה הרבים, אני מאמין כי נראה עוד ועוד אנשים מתחילים לעשות את צעדיהם הראשונים בתחום ה-ML בשנה הבאה. יתרה מכך, בשנה הקרובה אנחנו נראה כניסה לתחום מכיוונים שהם אינם קלאסיים, אלא דווקא מתארים או תחומי ידע אחרים (ניצנים שרואים כבר עכשיו). מהצד השני, נראה חברות מסורתיות או אפילו סטארטאפים ותיקים נכנסים גם הם לתחום ומתחילים לגשש את דרכם אל עבר שימוש חכם יותר בנתונים שלהם. צעד זה יצריך עוד כוח אדם מיומן שיוכל לספק פתרונות גם לחברות ותיקות יותר שירצו להעלות שלב ביכולות ניתוח המידע שלהן.
עוד נקודה שחזרה גם בשנה שעברה היא שמרבית העוסקים בתחום מתרכזים בגוש דן בכלל ובתל אביב בפרט. אני נוטה להאמין כי המגמה תשמר נוכח העובדה שמרבית הטאלנט נמצא באזור המרכז. עם זאת, כבר היום אנחנו רואים קהילות שצומחות בתחום ה-ML בירושלים ובחיפה, כך שיכול להיות ששנה הבאה הן יגדילו את חלקן בחלוקה הכוללת.
שינוי נוסף שעתיד להגיע בשנה הבאה הוא הדומיננטיות של TensorFlow עתידה אולי לרדת לטובת PyTorch שזוכה לפופלאריות רבה. עוד מוקדם לקבוע מי יעמוד בראש הטבלה ומה יבחר הקהל הישראלי בשנה הבאה, אך ניתן כמעט להיות בטוחים כי חלקה של PyTorch יגדל באופן משמעותי בשנה הבאה.
לסיכום, ניכר כי התחום כולו ממשיך לצמוח בארץ בכל היבט שתבחרו לבחון אותו. עצם הגידול המשמעותי במספר המשיבים לסקר והגידול האורגני במספר חברי הקבוצה מצביע על התעניינות גוברות מצד אנשי מקצוע רבים. לצד זאת, חשוב להדגיש כי ישנם לא מעט אתגרים שעדיין יש לטפל בהם לטובת המשך צמיחת התחום בארץ. כפי שעלה מן הנתונים, הבעיות העיקריות שהציפו חברי הקהילה היו מחסור בדאטה איכותי ובכוח אדם מקצועי. שני אלמנטים אלו קריטים לקידום התעשייה בארץ ולכל אחד מהם יש פתרונות מוגדרים שיגיעו הן מהתעשייה עצמה והן מפעולות רשמיות של הממשלה.



