לקט שבועי מתמלא של סקירות קצרות של #shorthebrewpapereviews, שבוע 12.08-18.08

12.08.23: DIVIDE & BIND YOUR ATTENTION FOR IMPROVED GENERATIVE SEMANTIC NURSING
https://huggingface.co/papers/2307.10864
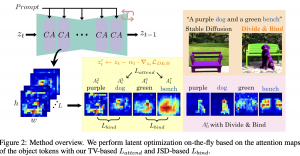
בטח שמתם לב שלפעמים שאתם מקבשים מודל גנרטיבי (נגיד midjourney) ליצור תמונה עם כמה אובייקטים (נגיד חתול, כלב, שולחן ומקרר) התמונה לא תמיד מכילה את כל האוייבקטים במיחד כשהתיאור הוא די ארוך ומכיל מספר רב של אובייקטים. היום ב-#shorthebrewpapereviews סוקרים מאמר המציע מענה לסוגיה הזו. קודם כל נבין למה לא תמיד אנו מצליחים להעביר למודל גנרטיבי (מודל דיפוזיה) את כל המידע. כדי להבין זאת נציין שהמידע (ייצוג) של הטוקנים מוזן למנגנון cross-attention לתוך השכבות הפנימיות של רשת UNet שהיא הלב של מודל הדיפוזיה (משערכת את הרעש בכל איטרציה). אז לפעמים טוקן טקסטואלי אחד ״גונב״ את כל ״תשומת הלב״ ואז הטוקנים האחרים פשוט לא באים לידי ביטוי ונעלמים מהתמונה. סוגיה נוספת שעלולה לקרות כאן היא attribute binding שבו פיצ'רים של אובייקטים מסוימים (כגון צבע או טקסטורה) משויכים לאובייקטים אחרים. המחברים מציעים להתמודד עם סוגיות אלו עם שתי גישות חדשות ל״הזזה״ של ייצוג הדאטה בכל איטרציה (semantic guiding) לכיוון של גרדיאנט הפונקציה המנסה לאכוף תכונות רצויות של מפות ה-attention. קודם כל הוא מנסה לכפות שונות מקסימיליח ביו מפות ה-attention של כל אובייקט בין טוקנים ויזואליים סמוכים (פאצ'ים של תמונה). לטענת המחברים ככה מונעים מאובייקט אחד להשתלט לנו על כל הטוקנים הויזואליים. התכונה השניה שמנסים לאכוף היא שוני בין מפות attention של אובייקטים שונים. את זה הם משיגים עם מקסום של מרחק Jensen-Shannon (JSD) בין מפות ה-attention המנורמלות בין כל שני האובייקטים. כאמור מזיזים את שערוך הייצוג של כל איטרציה של מודל דיפוזיה בכיוון שסכום מנורמל את שני ה״יעדים״ האלו.

13.08.23: TextDiffuser: Diffusion Models as Text Painters
https://huggingface.co/papers/2305.10855

מודלי דיפוזיה מצטיינים ביצירת תמונות מרשימות מתיאור טקסטואלי אך עדיין מתקשות ביצירה תמונות המכילות טקסט כחלק מהתמונה. למשל יצירת תמונה של כלב המחזיק שלט שכתוב עליו ״ברוך הבא הביתה״ עלולה ליצור תמונה עם טקסט שונה ולא ברור על השלט. היום ב #shorthebrewpapereviews סוקרים מאמר המנסה לתת מענה לסוגיה זו. המאמר מציע גישה דו-שלבית שבשלב הראשון נוצרת תמונה שבה נוצר את החלק בתמונה המכיל טקסט ובשלב השני מלבישים על התמונה זו את האובייקטים שיש בתמונה ושאר הפרטים (כגון טקסטורה ורקע). בשלב הראשון קודם כל בונים את שיכון (embedding) של הטקטס עם CLIP מאומן. אך להבדיל ממודלי דיפוזיה גנרטיביים אחרים מוסיפים לווקטור השיכון מוסיפים לכך שיכון נלמד של מילות המפתח (מחלקים את התיאור למילים שצריכות להופיע בתמונה ואלה שלא ובונים וקטורי שיכון שלהם). בנוסף מוסיפים לוקטור השיכון קידוד נלמד של רוחב של כל אות בתמונה ובנוסף מוסיפים לכך קידוד תלויה מיקום (positional encoding) נלמד. כל השיכונים הללו מחושבים באמצעות שני הטרנספומרים: אנקודר ודקודר. הראשון מאומן לקודד את הדאטה, השני מחשב Bounding Boxes (BB) עבור האותיות בתמונה ובשלב האחרון מרנדרים את התמונה לפי ה-BB שחישבנו והאותיות (המקודדות) ומגנרטים מסכות לאותיות. בשלב השני קודם כל מגנרטים תמונה כאשר הקלט הוא מסכות הנוצרות בשלב הראשון (בכמה צורות), השיכון של הטקסט והתמונה המורעשת (הרי זה מודל דיפוזיה). בנוסף ללוס הרגיל של מודל הדיפוזיה המודל נקנס על אי התאמה של מיקום האותיות בתמונה (הם מאמנים רשת לזיהוי מיקומים אלה).

14.08.23: Self-Alignment with Instruction Backtranslation
https://huggingface.co/papers/2308.06259
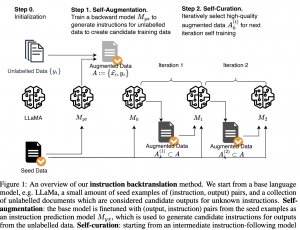
נניח שאתם רוצים לבצע יישור (alignment) עם דאטה מתויג (בסגנון של instruction tuning)של מודל השפה שלכם שאימנתם קודם על דאטה גדול ולא מתויג. נניח שיש בידיכם דאטה מתויג איכותי לא גדול במיחד ודאטהסט מאוד גדול ומגוון אך לא מתויג. המאמר שנסקו היום ב-shorthebrewpapereviews מציע שיטה אינטואיטיבית ואלגנטית להפקה של דאטאסט איכותי מתויג בגודל משמעותי מהדאטהסט הלא ממתיוג שיש ברשותנו. תהליך האימון מורכב משני שלבים עיקריים: קודם כל מכיילים מודל מאומן ליצור הוראה (instruction) מהתשובה עם הדאטהסט האיכותי המתויג שיש לנו. לאחר מכן מזינים למודל את ה״תשובות״ מהדאטהסט הלא מתויג כדי ליצור הוראה לכל לכל תשובה. שלב הזה נקרא self-augmentation. כמובן שלא כל הזוגות שיצרנו הם באיכות גבוהה ואנו מפלטרים אותם בשלב השני הנקרא self-curation. לוקחים מודל שמכויל רק עם הדוגמאות מהדאטהסט המתויג האיכותי (הקטן). מבקשים את המודל (עם פרומפט ספציפי) לדרג מ-1 עד 5 את התאמת התשובה להוראה. לאחר מכן מפלטרים את הזוגות בעלי ציונים הנמוכים. המחברים גם הציעו מה ש נקרא iterative self-curation שבמהלכו לוקחים את הזוגות (הוראה, תשובה) בעלי ציונים גבוהים, מכיילים את המודל עם זה. לאחר מכן ניתן למנף את המודל ל-self-augmentation (השלב הראשון) כדי ליצור דאטהסט מתויג איכותי עוד יותר. ניתן לחזור על התהליך כמה פעמים בתקווה לקבל דאטהסט מתויג גדול ואיכותי. מאמר אלגנטי ונחמד…

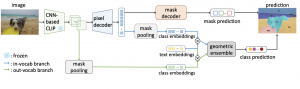
15.08.23: Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
https://huggingface.co/papers/2308.02487

בד״כ סגמנטציה בתמונות מתבצעת ב-2 שלבים. קודם מחשבים מסכות עבור כל האובייקטים בתמונה ובשלב השני מזהים סוגי האובייקטים. בזמן האחרון יש שימוש רב במודלים מאומנים(כמו CLIP) להפקה של ייצוג התמונה; בשלב 1 מזינים את התמונה למודל המאומן ובשלב 2 מזינים אותה יחד עם המסכות. היום ב #shorthebrewpapereviews סוקרים מאמר המבצע זאת בשלב אחד. למה זה טוב בעצם? כי במקרה הזה צריך להזין את התמונה ל-CLIP רק פעם אחת שזה מקצר משמעותית את זמן ההסקה והאימון כי CLIP זה מודל גדול וכבד. איך הם עשו זאת? קודם כל מעבירים את התמונה דרך CLIP מוקפא ואז מזינים את הייצוג המופק איתו ל-Pixel Decoder יחד עם ״שאילתות האובייקטים״ (סוג של פרומפט לחיפוש האובייקט) לחיזוי המסכות. במהלך האימון מצבעים התאמה בין המסכות ground-truth לבין המסכות שהוצאנו באמצעות אלגוריתם התאמה הונגרי (מזווגים מסכות הדומות ביותר). לאחר שבנינו את המסכות אנו צריכים לזהות את התוכן בתוך המסכות שמצאנו. עבור סגמנטציה עם מילון סגור (הקטגוריות ידועות) מצליבים את הייצוג (שיכון) של הקטגוריה במסכה (המופק באמצעות הפעלת רשת mask pooling) על הפלט של pixel decoder) עם ייצוג הטקטס (המופק עם CLIP) של כל קטוגוריה במטרה למצוא קטגוריה הטובה ביותר לכל מסכה. זה נעשה באמצעות חישוב דמיון cosine (עם טמפרטורה נלמדת) בין ייצוגים אלו כאשר קטגוריה עם דמיון מקסימלי עם ייצוג נבחרת כקטגוריה של המסכה. כדי לאפשר אוגמנטציה עם מילון פתוח (עבור קטגוריות שלא אומנו במהלך האימון) המחברים יוצרים ייצוג המסכה (מוסיפים ״נתיב״ למודל המקביל לנתיב המילון הסגור) רק מהשיכון המופק מהזנת התמונה ל-CLIP (דרך mask pooling). ואז ב-inference משתמשים באותה שיטה שהסברנו עבור המילון הסגור. בשלב משלבים את החיזוי עבור המילון הסגור עם הפתוח דרך geometric ensemble (סוג של מיצוע).
16.08.23: SOLVING CHALLENGING MATH WORD PROBLEMS USING GPT-4 CODE INTERPRETER WITH CODE-BASED SELF-VERIFICATION
https://huggingface.co/papers/2308.07921

אתם בטח שמתם לב למודלי שפה מסוגלים לתקן את ה״שגיאות״ שהם עושים אם מצביעים להם עליהם. כלומר אם מודל שפה ענה לא נכון הוא לפעמים מתקן את עצמו אם מבקשים ממנו לבדוק את תשובתו (לפעמים הוא ״מתקן״ גם תשובות נכונות אם מטילים בהם ספק). אבל מה אם נבקש ממנו לבדוק את תשובות דרך מימושם בקוד. היום ב-#shorthebrewpapereviews סוקרים מאמר שמציע שיטה לפתרון בעיות מתמטיות על ידי מודלי שפה באמצעות מימושם בקוד. הרעיון של המאמר הינו מאוד אינטואיטיבי ואלגנטי. מבקשים מודל שפה לפתור בעיה מתמטית שלב אחרי שלב תוך כדי שימוש ב-code interpreter ובנוסף מבקשים לוודא את התשובה עם אותו ה-code interpreter. כלומר המודל כותב קוד הנחוץ לפתרון הבעיה, מוודא שהפתרון נכון בעזרת הקוד ואם זה לא, הוא שוב כותב קוד המתקן את הטעות ושוב בודק אותה (לא הצלחתי להבין האם פעולות אלו חוזרות על עצמם יותר מפעמיים). מעניין כי לפעמים גם אחרי תיקון השגיאה המודל מאפיין את התשובה כלא נכונה או ״לא יודע האם נכונה״. המחברים גם מציעים שיטה נחמדה לפתור בעיות מתמטיות על ידי הרצות חוזרות של מודל שפה לאותה הבעיה המתמטית. לאחר מכן מחשבים ציון של כל תשובה על ידי משקול של תשובות כאשר כל תשובה שקיבלה ״נכון״ מקבלים ציון הגבוה ביותר, ״לא יודע״ מקבלת פחות ו״לא נכון״ מקבל משקל 0. המחברים מוכיחים שטריק פשוט זה מעלה את הסיכוי לקבל תשובה נכונה ממודל שפה.

17.08.23: Dual-Stream Diffusion Net for Text-to-Video Generation
https://huggingface.co/papers/2308.08316

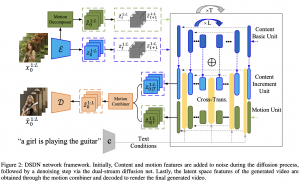
הגישות הראשונות ליצירה של וידאו מטקסט באמצעות מודלי דיפוזיה יצאו לראשונה לפני שנה וחצי ומאז השתדרגו משמעותית מבחינת איכות הוידאו, אורכו והתאמתו לתיאור. היום ניתן לעשות גם פרסונליזציה למודלים אלו כלומר ליצור וידאו עם אובייקט ספציפי (החתול שלכם). המאמר שנסקור היום ב-#shorthebrewpapereviews משדרג את הגישה הזו ומאפשר ליצור וידאו לא רק לאובייקט מסוים אלא גם לדפוס תנועה מסיום (הנגזר מוידאו אחר למשל). וכל זה בהתאמה לתיאור הטקסטואלי. איך מאמנים מודל כזה? מזינים למודל את הוידאו ובשלב הראשון מעבירים כל פריים דרך האנקודר להפקה של ייצוגו הלטנטי (עם VQ-VAE). מהייצוג הזה מאמנים מודל המפרק את הייצוג הזה את ייצוג התנועה בוידאו (בין הפריימים) לבין ייצוג התוכן של הוידאו (כל אחד מהם הוא מערך של וקטורי ייצוג) – זה נעשה באמצעות Motion Decomposer. מערך וקטורים אלו מוזן למודל דיפוזיה משלו (מכאן בא השם dual stream) שעושים את קסמיהם הרגילים. פלטי מודלי דיפוזיה אלו מוזנים לרשת ש״מערבבת״ אותם ומוציאה שני ייצוגים מסונכרנים של תנועה ושל התוכן. בסוף שני ייצוגים מסוכנרנים אלו מוזן לרשת המשלבת אותם ובונה ייצוג של וידאו שעובר דרך הדקודר כדי לגנרט וידאו. כאשר רוצים לגנרט וידאו לייצוג תנועה נתון מכיילים את המודל על ידי מזעור לוס השחזור את ייצוג התנועה מהייצוג הוידאו המגונרט.
סקירה זו נכתבה על ידי עדן יבין
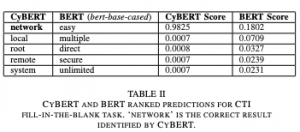
18.08.23: CyBERT: Contextualized Embeddings for the Cybersecurity Domain
https://mdsoar.org/bitstream/handle/11603/25498/1117.pdf

מודלי שפה הראו את היכולת שלהם לעבוד בהמון תחומים בתוך עיבוד שפה טבעית. אחד התחומים שבהם ציפו להשפעה גדולה של מודלים אלו הוא תחום אבטחת המידע או בשמו היותר מוקר תחום הסייבר. במאמר ששמו הינו CyBERT הראו לראשונה את השילוב של מודלי שפה גדולים (מודל BERT) בתחום הסייבר. החוקרים ניסו להראות איך שיפור של BERT הקיים יכול להביא לשיפור ניכר של אותו מודל במשימות שונות כגון זיהוי אוביקטים הקשורים לתחום הסייבר או סיווג של מילה לאוביקט המתאים לה. למשל, ניתן לראות תוצאות של המשימה האחרונה המוזכרת בה המודל נאלץ לסווג מילה מתחום הסייבר לאוביקט המתאים לה. איך ביצעו זאת? על ידי הרחבת האימון של BERT עם מספר שלבים נוספים: – אוספים מסמכים רבים מתחום הסייבר – מנקים את המסמכים והופכים אותם לרשימה של טוקנים. – את הרשימה של טוקנים מוספים למילון של ה-Tokenizer של BERT. בנוסף, מוסיפים למטריצת ה-Embedding הרגילה של BERT את הטוקנים עם ערך רנדומלי. מבצעים אימון נוסף של Masked Langue Modeling, בה המודל נדרש להשלים מילות חסרות במשפטים. ככה הערכים הרדומלים מתעדכנים. – מבצעים אימון נוסף בהתאם למשימה, למשל אימון מפוקח של זיהוי אוביקטים של סייבר במשפט. המאמר מעניין אותי במיוחד לא רק בשל היותו בתחום הסייבר אלא בשל התזכורת שהוא נותן כיצד ניתן לבצע אימון נוסף של מודלי שפה גדולים על תחומים חדשים.