D-STEP: Dynamic Spatio-Temporal Pruning

סקירה זו היא חלק מפינה קבועה של סקירת מאמרים חשובים בתחום ה-ML/DL, בהם מוצגת בעברית גרסה פשוטה וברורה של מאמרים נבחרים. במידה ותרצו לקרוא את המאמרים הנוספים שסוכמו, אתם מוזמנים לבדוק את העמוד שמרכז אותם תחת השם deepnightlearners.
לילה טוב חברים, היום אנחנו שוב בפינתנו deepnightlearners עם סקירה של מאמר בתחום הלמידה העמוקה. היום בחרתי לסקור מאמר שאני שותף בכתיבה שלו, יחד עם שותפים מ-SIRC – Samsung Israel R&D Center:
D-STEP: Dynamic Spatio-Temporal Pruning
מאת: Avraham Raviv, Yonatan Dinai, Igor Drozdov, Niv Zehngut and Ishay Goldin.
פינת הסוקר:
המלצת קריאה: מומלץ למי שמתעסק עם אופטימיזציה של רשתות, רשתות לניתוח וידאו ורשתות שמיועדות למכשירי קצה (מובייל, IoT וכדו').
בהירות כתיבה: גבוהה.
רמת היכרות עם כלים מתמטיים וטכניקות של ML/DL הנדרשים להבנת מאמר: נדרשת היכרות בסיסית עם רשתות קונבלוציה. המאמר קל להבנה וכמעט לא מכיל נוסחאות מתמטיות.
יישומים פרקטיים אפשריים: יצירת רשתות דינמיות המקנות שיפור ב-inference time וצריכת סוללה כמעט ללא פגיעה בדיוק הרשתות.
פרטי מאמר:
לינק למאמר: זמין כאן
לינק לקוד: זמין כאן (PyTorch)
פורסם בכנס: BMVC2022
מבוא:
רשתות נויורנים בנויות לרוב באופן כזה שכל קלט שיכנס אליהן יעבור דרך כל מבנה הרשת, וכל פעולות החישוב (קונבולוציות, אקטיבציות וכו') יתבצעו ללא תלות בקלט. הפעלת כל הרשת הינה פעולה שעלולה להיות יקרה חישובית, וישנן דרכים רבות לחיסכון בחישובים. דרך נפוצה מאוד הינה Pruning – חיתוך (הורדה) משקולות/שכבות מהרשת המאומנת. גישה זו מתבססת על העובדה שרשתות נוטות להיות over-parametrized, כלומר, אין באמת צורך בכל המשקולות שברשת על מנת לבצע את המשימה שעליה היא אומנה (להרחבה: The Lottery Ticket). חשוב להדגיש שגם כשמשתמשים ב-pruning, צריך (ואולי חייבים) להתחיל מאימון של רשת גדולה, המצליחה להיות רובסטית ביחס למשימה המיועדת, ורק לאחר מכן ניתן לגזום משקולות או אפילו שכבות. כדאי להזכיר שיש תחום מקביל וקשור מאוד הנקרא Network Architecture Search, או בקיצור NAS, ובו לוקחים רשת קיימת ומנסים לחפש ארכיטקטורה טובה יותר עבור אותה משימה.
ישנן הרבה מאוד עבודות בנושא pruning, והמשותף לרובן שהוא נעשה בצורה סטטית, כלומר – מאמנים רשת גדולה, לאחר מכן גוזמים אותה, וכך מתקבלת הרשת הסופית שהינה כעת קבועה ולא משתנה יותר. לעומת רוב העבודות, ישנן מספר עבודות המבצעות את ה-pruning בצורה דינמית תוך כדי Inference. רשתות אלו מאומנות בצורה רגילה, ואז כתלות בקלט הרשת משתמשת רק בחלק מהמשקולות. אם לדוגמה הרשת מזהה בשלב מוקדם שתמונה שנכנסת אינה מכילה אובייקטים אלא היא כולה רקע, אז ניתן לא להפעיל את המשקולות בהמשך הרשת ובכך לחסוך הרבה חישובים. בדומה לכך ניתן לדלג באופן דינמי על ערוצים מסויימים בביצוע פעולות קונבולוציה, אם למשל אנו מזהים שאין בהם מידע מעניין (להרחבה: Dynamic Channel Pruning, Dual Gating). חשוב לשים לב ששיטות אלה, המבצעות Inference בצורה דינמית, אינן מבצעות ממש pruning של משקולות, אלא כתלות בקלט מדלגות על חלק מהחישובים וכך נעשה מעין pruning דינמי. הרעיון מאחורי התהליך הוא למצוא פעולות חישוביות שהן redundant (יתירות) ביחס לקלט ולא לבצע אותן, וכך ה-Inference מתבצע בצורה יותר מהירה ובפחות חישובים.
יש מספר סוגי מידע שיכולים להיות מיותרים, ולעיל ציינו דוגמה לשניים כאלה – אינפורמציה מרחבית שאינה רלוונטית (כמו למשל רקע) וערוצים (channels) של הקונבולוציה שאינם מחזיקים פיצ'רים חשובים. המאמר הנסקר מתעסק בדומיין של וידאו, ומשלב את שני סוגי היתירות האלה יחד עם temporal redundancy שיכול להווצר כתוצאה ממידע שאינו משתנה בין פריימים שונים של אותו סרט. כלומר, המנגנון המופעל ברשת המנתחת את הוידאו מחפש אחר יתירויות בשלושה ממדים – Spatial, Temporal and Channel wise. כמובן שמנגנון זה דורש חישובים נוספים מעבר לפעולה המקורית של הרשת המופעלת על הוידאו, אך בסך הכל יש חיסכון משמעותי – במאמר מראים שניתן לחסוך יותר מ-15% מסך החישובים של הרשת בלי לפגוע בדיוק שלה, ולחילופין ניתן לקבל מודל שחוסך 50% מהחישובים (!) עם ירידה של בערך 1.5% ב-accuracy. מלבד הביצועים ביחס למודל סטטי, המאמר מספק גרף trade-off של accuracy ביחס לFLOPs טוב משמעותית ממודלים דינמיים קודמים. בנוסף, השיטה המוצעת מאפשרת למשתמש לבחור בעצמו כמה חישובים הוא מעוניין לחסוך, ובהתאם לכך לאמן מודל שיתן את מספר החישובים הרצוי תוך ירידה יחסית קטנה ב-accuracy. [הערה: כמובן שכמות החישובים הנדרשת משתנה בין סרט לסרט, הרי זה כל הרעיון – שהרשת תהיה דינמית כתלות בקלט. הספירה של החישובים הינה ממוצע על מספר גדול מאוד של סרטים, כאשר הסרטים מגוונים ומכילים מאפיינים שונים].
תקציר המאמר:
כאמור, המאמר מתעסק בדומיין של וידאו, והוא מציע דרך חדשה ויעילה לבצע Inference דינמי, בו הרשת לא מבצעת את כל כל החישובים עבור כל קלט, אלא היא אדפטיבית ביחס אליו ומנסה למצוא חישובים מיותרים ולהמנע מלבצע אותם. בשביל לעשות זאת, יש רשתות קטנות הנקראות Policy networks שתפקידן לזהות את אותן יתירויות. במאמר יש שני סוגים של רשתות כאלה:
א. רשת שתפקידה למצוא יתירות מרחבית.
ב. רשת שתקפידה למצוא ערוצים שלא צריכים לבצע עבורם את הקונבולוציה. הימנעות מחישוב הקונבולוציה יכול להגרם משתי סיבות – ערוץ שמחזיק מידע לא רלוונטי וממילא ניתן לדלג על החישוב שלו (Skip) או ערוץ שעבורו המידע מהפריים הקודם לא השתנה, ולכן ניתן להשתמש בחישוב שהתבצע בפריים הקודם (Reuse).
באופן הכי כללי ניתן להוסיף לכל פעולת קונבולוציה את שתי רשתות ה-policy, כך שהתהליך נראה כך:

הקלט בשכבה l עובר קודם כל ברשת policy שתפקידה לחפש אזורים פחות חשובים. לשם כך, הקלט, שהינו בממד H x W x C, עובר דרך Adaptive Average Pooling על מנת לצמצם את ממד הערוצים ולקבל דאטה בממד H x W. התוצאה שמתקבלת מחולקת ל-patches (בפועל כל patch הוא ריבוע של 8×8), וכל patch נכנס לרשת policy, המחליטה אם הוא מעניין או לא. כל ה-patches שהרשת החליטה עבורם שהם פחות חשובים מתאפסים, ובכך בהמשך יחסכו חישובים.
בשלב השני כל יש רשת שתפקידה להחליט עבור כל ערוץ האם יש לחשב עבורו קונבולוציה מחדש, או שאפשר לדלג על החישוב (מפני שערוץ זה לא חשוב או שניתן לקחת את התוצאה מהפריים הקודם). עבור כל ערוץ, הקלט של הרשת הזו מורכב משני חלקים – Adaptive Average Pooling של הערוץ מהפריים הנוכחי ו-Adaptive Average Pooling של הערוץ מהפריים הקודם. הרשת מוציאה אחת משלוש אופציות – Skip, Reuse או Compute. אם הרשת הוציאה Skip, אז הערוץ הזה לא חשוב וניתן לאפס אותו. אם היא הוציאה Reuse אז ניתן לקחת את הערוץ מהפריים הקודם בשכבה הבאה (l+1). אם לעומת זאת הערוץ חשוב והוא השתנה מהפריים הקודם, הרשת תקבע שיש לחשב עבורו את הקונבולוציה באופן מלא.
בשלב הסופי, הרשת הכללית מחשבת את הקונבולוציות עבור הערוצים שרשת ה-policy הוציאה עבורם "Compute" ומבצעת מיזוג בינם ובין הערוצים המחושבים מהפריים הקודם שעבורם הרשת הוציאה כעת "Reuse". באופן הזה מתקבלת מפת פיצ'רים חדשה, שבה יש ערוצים שהם כולם מאופסים, ויש ערוצים שבהם חלקים מאופסים בגלל שמבחינה מרחבית הם פחות חשובים.
אחד האתגרים שיש במנגנון זה הוא ההחלטות הדיסקרטיות שהרשתות הקטנות צריכות לקבל. בסופו של דבר, הרשת מוציאה הסתברות לכל אחת מהאפשרויות, ויש לבחור רק את זו עם ההסתברות הכי גבוהה (הרשת הראשונה מחליטה עבור כל patch האם הוא Compute או Skip, ואילו לרשת השניה יש שלושה מוצאים – Skip, Reuse, Compute). הבעיה בפעולה זו, שבעצם עושה בינאריזציה למוצא של רשת ה-policy, נעוצה בכך שהיא אינה גזירה, וממילא לא ניתן לחשב עבורה גרדיאנטים. ישנם מספר פתרונות מקובלים (למשל: Reinforce), ובעקבות עבודות קודמות במאמר זה בחרו להשתמש ב-Gumbel-SoftMax, שיטה המאפשרת להפוך את ההתפלגות הדיסקרטית לרציפה ולדגום ממנה, ובכך להפוך את הפעולה שמבצעת רשת ה-policy לגזירה.
בסה"כ המנגנון הזה מאפשר חיסכון רב של חישובים, בלי פגיעה בדיוק של הרשת. אמנם התווספו עוד פרמטרים וישנו חישוב נוסף שמתבצע על ידי הרשתות החדשות, אך במבט כולל זה יחסית זניח – הן מהוות פחות מ-0.1% מסך הפרמטרים ברשת והחישובים שהן צורכות הוא בסדר גודל של 1-2% מסך החישובים של הרשת הפועלת על הוידאו. החיסכון לעומת זאת הוא גדול מאוד – ניתן לחסוך כ-15% מהחישובים ללא פגיעה בדיוק, ועם פגיעה יחסית קטנה ניתן לחסוך כמחצית מחישובי הרשת, שזה משמעותית גדול יותר מה-overhead שנוצר בעקבות הוספת הרשתות הקטנות.
מלבד החיסכון בחישובים, יש יתרון נוסף לשימוש ברשת ה-policy השניה. רשתות המעבדות וידאו צריכות למדל איכשהו את הממד הטמפורלי (כלומר את השינוי של הפריימים בזמן), ורשת ה-policy מבצעת זו על ידי ה-Reuse. כאשר לוקחים ערוץ מפריים אחד לפריים העוקב אליו, בעצם משלבים מידע מנקודות זמן שונות, ובכך מאפשרים לרשת ללמוד על השתנות תמונת הקלט כתלות בזמן.
סיכום והישגי המאמר:
המאמר מציג שיטה לביצוע Inference דינמי (או: pruning אדפטיבי של משקולות וערוצים) עבור action recognition בוידאו. הדינמיות מתבצעת באמצעות רשתות קטנות המסייעות לחסוך חישובים תוך זיהוי יתירות במרחב, בזמן ובממד הערוצים. המאמר משווה את עצמו עבור כמה דאטהסטים של action recognition לעבודות מאותו תחום ולעבודה סטטית בה אין ניסיון לחסוך בחישובים. הדאטהסטים מגוונים באופי שלהם, כאשר בחלקם יש יותר תנועה ובאחרים פחות, ובנוסף הם שונים באופן התזוזה שמתבצעת (מצלמה קבועה ואובייקטים זזים או אובייקטים קובעים ומצלמה זזה). ברוב המקרים הטרייד-אוף בין דיוק לבין כמות חישובים של המודל המוצע עדיף מאשר עבודות קודמות, כמו למשל רשת ResNet18 על דאטה סט Something-V2:

כדאי להזכיר שמלבד הטרייד-אוף המוצג, המנגנון מאפשר למשתמש לבחור נקודת עבודה כרצונו: ניתן לבחור כמות חישובים רצויה, למשל 60% מהמודל הסטטי, ולקבל מודל החוסך 40% מהחישובים תוך פגיעה קלה בלבד בביצועים. כתלות באפליקציה ובצורך להיות מדויק ניתן באופן גמיש לאמן בקלות מודל שיתאים לצרכי המשתמש במובן זה של יחס בין דיוק לכמות חישובים נדרשת. כך למשל, עבור מגוון דאטה סטים, ניתן לייצר כמה נקודות עבודה – אחת בעלת דיוק גבוה, שניה בעלת חיסכון גדול בחישובים, ושלישית הממצעת בין השתיים (וכמובן ניתן לאמן עוד ועוד מודלים שיפלו על הגרף):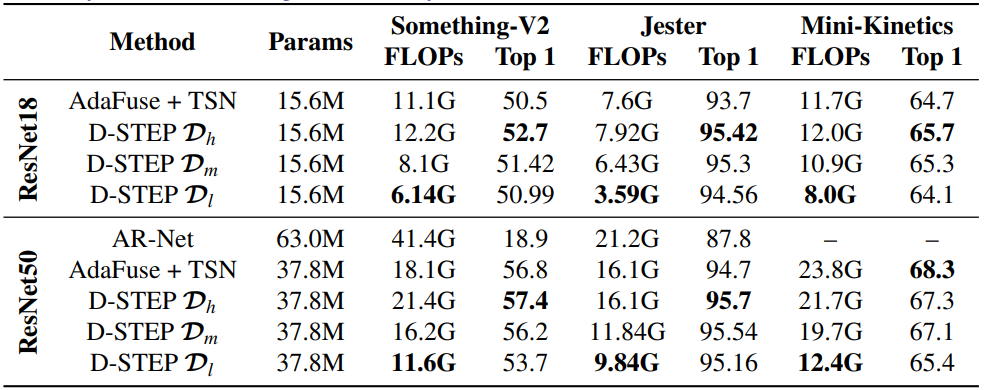
עוד כדאי לציין בהקשר של ניסויים ותוצאות – למרות שבאופן כללי ניתן לשים את רשתות ה-policy לפני כל קונבולוציה, אמפירית יותר מוצלח לשים בכל בלוק של ResNet רק לפני הקונבולוציה הראשונה.
נ.ב.
הדומיין של אימון רשתות וידאו הוא יחסית מורכב ודורש הכרה של התחום ושיטות שונות לעיבוד וידאו בצורה איכותית, והוספה של מנגנון דינמי עוד יותר מסבכת את העסק. עם זאת, המאמר כתוב בצורה פשוטה ומציע מנגנון יחסית אינטואיטיבי וידידותי למציאת כלל היתירויות שיתכנו ברשת שכזו. התוצאות מעניינות מאוד, ויכולות לשמש כבסיס למודלים שרצים בלייב על חומרות ומכשירים דלי משאבים.
בשולי הדברים כדאי להרחיב מעט על השימוש של 2D conv ברשתות וידאו. כיוון שיש משמעות לממד הטמפורלי (שינוי הפריימים בזמן), הרשת חייבת איכשהו לעבד אותו ולהבין את התנועה שמתרחשת על מנת להגיע לתוצאות טובות. יש הרבה עבודות שמשתמשות ב-3D conv, בו מלבד לממדים של התמונה עצמה יש גם ממד זמני. החיסרון בגישה זו הוא כמות החישובים שקרנל כזה צורך. בעיה דומה ואף חריפה יותר קיימת בטרנספורמים לוידאו, שמלבד העובדה שהמודלים גדולים מאוד, גם כמות החישובים בהם היא עצומה, מה שהופך אותם לכמעט לא פרקטיים למכשירים דלי משאבים. עבור מכשירים כאלה, התפתחו שיטות המתבססות על 2D conv, המבצעות את המידול הטמפורלי באופן אחר (למשל: TSM). כפי שהוזכר לכיל, במאמר זה המידול טמפורלי התבצע באמצעות Reuse (והוא לא במקום TSM אלא בתוספת אליו).
#deepnightlearners
הפוסט נכתב על ידי אברהם רביב.


